Blog
Approval Queues Are the Runtime for Agentic AI Workflows
Approval queues turn human-in-the-loop AI from a button into durable runtime state, with policy, checkpoints, ownership, traces, and receipts.
Jun 29, 2026

An exception queue is the next agent interface to embed.
Dull. An exception queue is fundamentally simple. All enterprise autonomy requires is for the agent to create a review item (e.g. an Approval item) and park its state. Then it waits for someone to make a decision, and resumes execution when done. If the AI agentic workflow depended on someone physically being present to “review” the AI (e.g. by staring at chat) then it would simply be another chat app, dressing up in a hard hat for work.
LangChain’s ambient-agent framing of Listen, Act, Ask (notify, question, review) applies well here, as these ambient agents are listening to streams of events, acting in the background, and then asking the human at the right time for notify, question, or review, as applicable ambient agents listen to event streams, act in the background, and ask for notify, question, or review at the right moments.
This dull object is at the center of the production design for approval items.
This item must carry the action, the arguments for the action, the risk reason, the owner of the item, the decisions that are allowed, the checkpoint pointer, the trace link, a timeout for the item, an escalation path for the item and finally a receipt for when the item was approved. Without this set of information to carry, a review of an item is just a button press. With this set of information the approval queue is where the runtime passes control to a human and then gets it back cleanly.
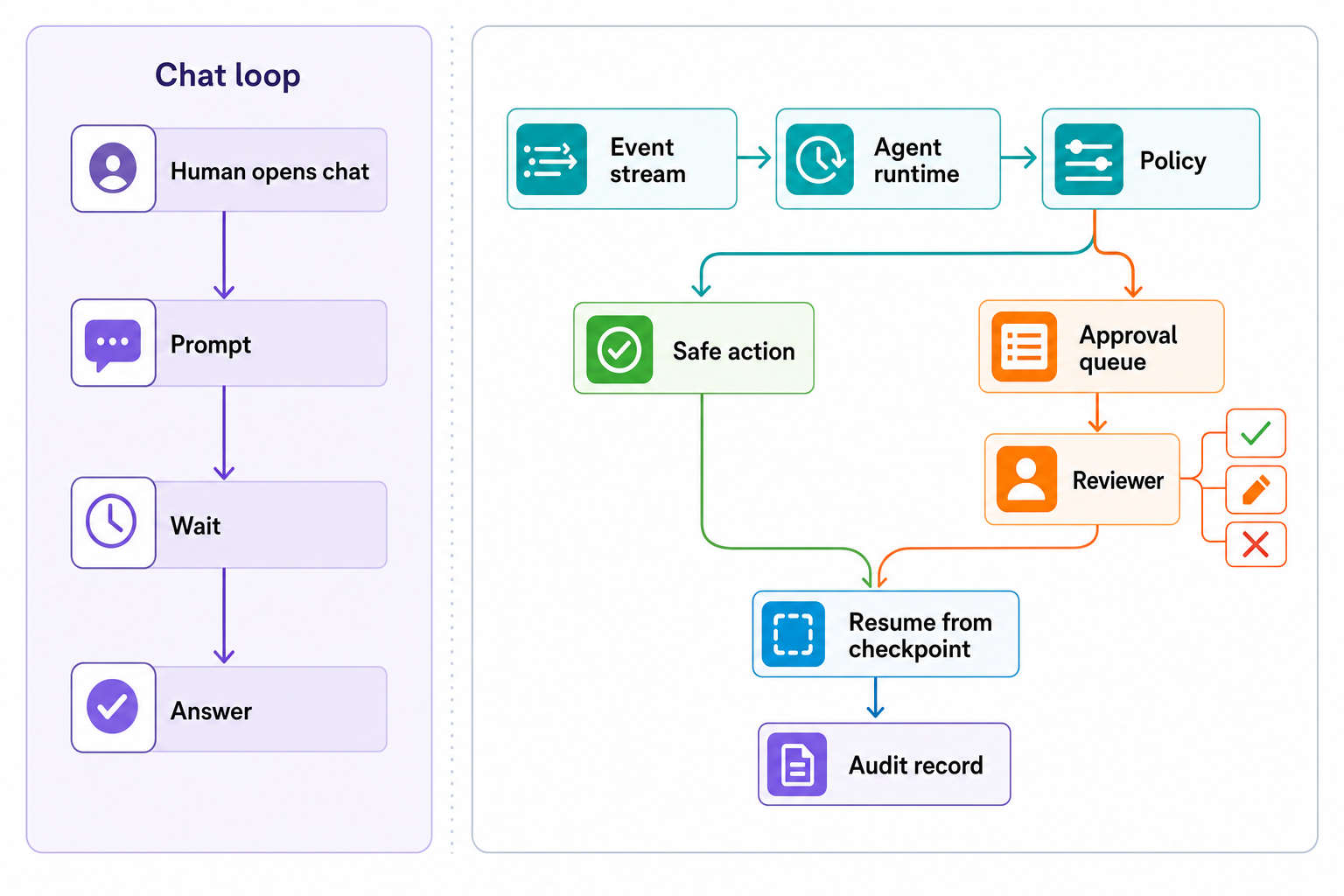
The agent does not pause in the abstract
A production agent pauses at a precise boundary.
It wants to send an email. It wants to update a CRM record. It wants to run a database migration. It wants to refund a customer. The phrase “human in the loop” has been flattened into a checkbox. The useful design question is what the runtime does when the model proposes a side effect that carries business risk.
Current Human-in-the-Loop middleware is implemented as tool-call policy. So the docs for HumanInTheLoopMiddleware, interrupt_on, and allowed decisions like approve, edit, reject, and respond, all of that makes sense as a tool-call policy problem. That is, the model proposes an action, policy then decides whether that action can in fact be executed, and human decision is then returned as structured input to the graph. And the input is structured, not just “vibes, put human in the loop for this and see what they do”.
On the other hand, when we look at the runtime of a production agent, we see that the interrupt model of LangGraph (which is used for HITL as well) makes the runtime even harder to ignore. While graph execution is interrupted by an HITL request, all state is saved, and the request is processed through the persistence layer. The runtime then waits indefinitely for input from the outside, and after that, graph execution is resumed from the point where it was interrupted, on the same thread, i.e. in the same session, using Command(resume=…), where thread_id is the id of the thread (i.e. session) where execution was interrupted Interrupts pause graph execution, save state through the persistence layer, wait indefinitely for outside input, then resume through Command(resume=...) using the same thread_id. This is queue semantics. A unit of work pauses, state is saved, and only then approval is asked for.
OpenAI or OpenAI’s Agents SDK has taken a similar approach. Their human-in-the-loop flow pauses sensitive tool calls as interruptions, converts the result into RunState, and resumes the exact same run after approval or rejection.
The approval item is the real interface
I have seen teams underbuild the approval of actions because the UI looks so simple: a list, a card, three buttons for create, edit, delete, maybe a diff, and fine.
We treat the queue item for the approval action as a canonical representation for that action. That item must contain information on why the action was put into the queue for approval in the first place. It must contain information on the original arguments that were made for that action. It must contain the trace for the recommendation made by the agent. It must contain information on who can take action for this item. It must describe the set of legal actions for this tool. It must make a decision on whether editing the arguments for this action is safe or not, versus rejecting the whole branch of actions in its entirety. After a decision has been made, it must resume the same graph state instead of starting a fresh run from a summary.

So the policy decision before calling the tool in policy before the tool call is important to have an approval queue that is strong and embedded in the action boundary, versus a generic “approval” modal in a corner of the app. It needs to be where identity and permissions and the current state of things and the trace that the team is running under and all the side effects of what the team is doing as a result of this approval.
A weak approval item would read “approve email?” whereas a strong approval item would read “send_email to acct@example.com, generated from ticket 18422, contains refund language, crosses external communication policy, reviewer is support lead, allowed decisions are approve, edit, reject, timeout is 4 business hours, checkpoint is thread-9f2, trace is linked, final receipt will attach to the customer record.”
That difference looks clerical until the first incident.
After the incident, the queue record becomes the shared record the shared record. That record contains the approved action, the proposed action, the changes, the policy that queued it, whether the graph resumed correctly, and whether a receipt was stored after the tool call. All of these questions determine whether the workflow is operable or merely lucky.
Autonomy already includes intervention
The production data backs this up. In the MAP paper, “Measuring Agents in Production” the authors report on a survey of 306 practitioners plus 20 detailed case studies from 26 domains. The survey found that 68% of production agents execute 10 steps or fewer before human intervention, and 74% rely primarily on human evaluation.
The agents in Enterprise use of Agents are bounded systems, i.e. they are “good until the next uncertainty / policy boundary / irreversible action / missing context / accountability break”. And that handoff has to be cheap, precise and reviewable.
Agent evaluation after release must continue to ensure that the rules and policies a production agent is executing against are correct agent evaluation has to continue after release. Approval decisions are production labels for others in the workflow. Edits show prompt gaps. Rejections show policy holes. Timeouts and errors show ownership problems or risk routing mistakes. The queue itself becomes a data source for improving the workflow of a production agent.
HumanLayer’s 12 Factor Agents makes the same architecture point from another angle: production-grade agents work better as deterministic software with LLMs in scoped decision points production-grade agents work better as deterministic software with LLMs in scoped decision points. A review queue is one of those deterministic pieces. It owns control flow while the model handles ambiguity inside a boundary.
Approval fatigue is a design failure
Every action can be cast as a prompt, thus reviewer just click through permission prompts. The quiet part Anthropic finally publicly confessed recently when they introduced Claude Code to auto mode for generating code, and revealed the approval stats of permission prompts: 93% Claude Code users approved 93% of permission prompts. A system of approval for such a safety-critical activity is simply asking users to play pretend and pretend that they’re doing something safe, while their attention is decaying as they get bounced through window after window of theater.
Containment for safety is about reducing risk for human reviewers and limiting blast radius. Anthropic has written up the same containment point: human supervision reduces risk, but blast-radius control also comes from sandboxes, filesystem limits, network egress rules, credential boundaries, and product-specific containment.
Low risk actions flow, medium-risk actions batch, high-risk actions interrupt a human owner, and forbidden actions die before they hit a reviewer. An approval queue with risk routing becomes part of the agent control plane: registry, identity, policy, observability, cost, ownership, and retirement around agents that act in real systems.
The approval policy also has to describe what the reviewer can do. Approve is not enough. Edit, reject, and respond mean different things in code. LangChain docs describe all of these.
The owner is the team running the workflow
Model providers will send approval primitives to use in a workflow, frameworks will expose interrupts for durable pause and resume, and platforms offer review screens that look nice in a demo.
Then the queue policy of the workflow has to match the business process as well. A sales email, a payment approval, a database change or a fix of a vulnerability should not share the same approval process. These actions have different ownership, risks, evidence, rollback paths, and audit needs. Model providers cannot implement that organizational knowledge in a model and hand over an approval primitive to the framework.
customer-facing actions are approved as a package that includes failure: generated output, action taken with that output, who approved it, what system of record receives a receipt, and how support responds after the fact. We wrote about this at length already: customer-facing actions need approval paths.
I keep making the same mistake: showing off the shiny high-level stuff but leaving out the boring implementation details. Store the queue item outside the model context. Attach the trace to every decision. Give each decision an owner. Capture the before and after. Log the tool receipt and the resumed checkpoint. Put timeouts and escalation in the queue rather than in a never-opened runbook. Feed edits and rejections back to evals with a full audit log.
The “No Last Mile” paper by Arun Narayanan et al. goes into more detail on how evaluation, auditing, exception handling, giving and taking rubrics, and constant updating of the system, as it changes with time, is a persistent human-data task. Approval queues make that work operational.
The queue is where autonomy becomes accountable
Enterprise autonomy is an agent that knows when to create a review item, who owns it, what decisions are legal, how long to wait, where to pick up paused work, and what evidence to leave behind. Less magic. That is a lot better than the magic that keynote audiences adore. Magic is a terrible operating model.
So that’s the enterprise version of autonomy: good old workflow management. The agentic AI workflow that survives production has less chat in the center and queue semantics underneath. Events arrive, policy routes them, the agent acts where it can, risky work pauses with state, a human makes a decision with the right context, the graph resumes and the receipt for the work is left behind for evaluation after the work is released.
Don’t ask the generic question around human approval support for the agentic AI workflow. Instead, ask where the approval item lives, what state it holds, how decisions get routed, how the graph resumes after a decision point, and what record gets left behind to feed evaluation post release. The answer to these questions gives a buyer a much better sense of production readiness than another autonomy slider.
/Contact Us

Modernize your legacy with Focused
Get in touch