Extreme collaboration
Our engineers will dive into any stack, solve the hardest problems, and deliver work continuously and collaboratively to get to the right answer together, side-by-side.
We build evals that test accuracy, saftey and performance before your users do
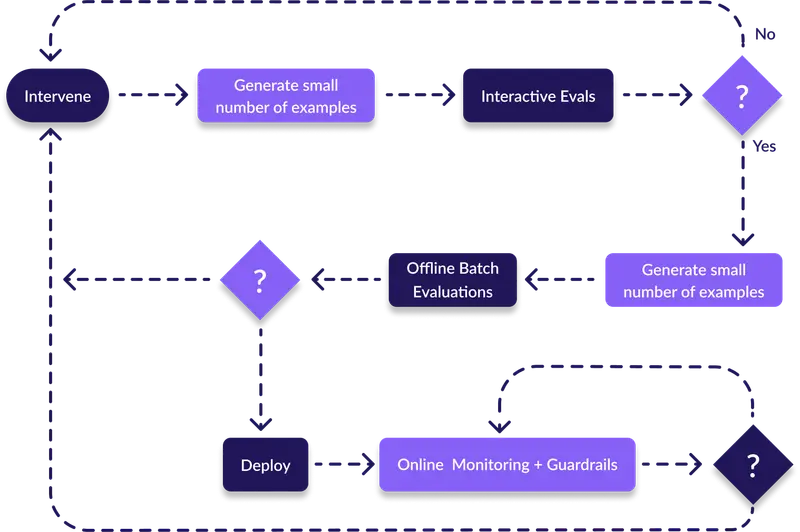
Your AI works perfectly in demo. Then it hits production and starts giving customers wrong account balances. We use evaluation frameworks like LangSmith to test your AI against the chaos of real-world usage.

Anthropic releases a new Claude, Google drops the next Gemini, or OpenAI surprises everyone, your evals tell you if switching will improve or break your agents. No guessing. No manual testing. Just data.
Evals enable your developers to iterate on prompts without the fear of regression. Add a new example and the agent starts over correcting, wonky spacing breaks tool calling, evals stop these breaking changes before they get to production.
Our designers and software engineers integrate fully with your team to deliver exceptional software and ensure your people have the skills and resources to keep growing.

Our engineers will dive into any stack, solve the hardest problems, and deliver work continuously and collaboratively to get to the right answer together, side-by-side.
We build and deliver quality working software. To get there, we prioritize incremental changes to complex systems, maximizing impact and minimizing operational disruption.
Good software solves problems—and it makes growth possible. We deliver the product you need and the knowledge your team needs to run with it. Doing our job well means working ourselves out of a job.