
There are a ton of tutorials out there on how to get started writing basic Retrieval-Augmented Generation (RAG) chains. Perhaps you've built a chatbot or created a chain to extract structured data from unstructured PDFs. But how do you know if your prompts are improving and getting the results you want? Let’s take a look at LangSmith, a tool that we heavily use at Focused. It’ll help you improve your RAG results quickly, and you’ll be able to create suites of tests to ensure your chains aren’t backsliding with minor prompt changes.
Intro to LangSmith
Small prompt adjustments can have significant impacts. Maybe the results are good, and you want to implement them. Maybe they completely change your results for the worse. But how do you know if your application is improving if the results from an LLM are non-deterministic? Fortunately, we have tools that let us examine exactly what happens when information flows into an LLM.
One of those tools is LangSmith, an application that traces the exact workings of your RAG chains. It provides detailed visibility into your prompts as they enter the LLM and shows which documents are retrieved from vector stores. The ability to view traces will give you the tools to correct any issues you see in your applications.
LangSmith also provides evaluation tools for your RAG chains. To run evaluations, you’ll create a dataset. A dataset is a collection of expected inputs and outputs from a call to your RAG chain, which you can use to test improvements to your application as you iterate toward a particular result. These datasets help you measure and track improvements in your application's performance.
Getting Started with LangSmith
Getting started with LangSmith is easy:
- Set up a free account on LangSmith’s website and create an API key.
- Install the
langsmithpackage. - Expose your API key in your environment variables:
LANGSMITH_TRACING=true
LANGSMITH_API_KEY=<your-api-key>
4. Load your environment variables in locations where you’re making LLM calls, and run your RAG chain.
Congrats! You should be able to see traces in your application now when you run an LLM step.
Tracing
Before you start evaluating your application, let’s talk about tracing. Traces are like telemetry for your RAG chains. You can see what goes in/out of vector dbs, llm calls, and how your prompts are formed.
Tracing in LangSmith alone is worth using the tool. It’s helped me diagnose so many issues.
LangSmith allows you to see:
- How many tokens are you using?
- Why are RAG chains running slowly?
- Are steps in your RAG chain malformed?
- What happens when you change LLM models?
Tracing works both locally and in the cloud, allowing you to monitor your application's real-time usage in production.
To enable tracing, we need to:
- Add the
@traceabledecorator to the method you’re interested in tracing. OR you can use one of the wrappers for an LLM, which hooks into LangSmith tracing. - Run your RAG chain
That's it! Using the @traceable decorator is a preferred approach because it tracks the inputs and outputs of your specific method. Having this input/output data readily available makes the evaluation phase of your application much smoother.
An example of a traceable method looks like this:
@traceable
def summarize_transcript(file_text):
PROMPT_TEMPLATE = ChatPromptTemplate.from_template(summarize_transcript_prompt)
rag_chain = RunnablePassthrough(
transcript=itemgetter("transcript")
) | PROMPT_TEMPLATE | llm
return rag_chain.invoke({
"transcript": file_text,
}).content
And here’s the trace:
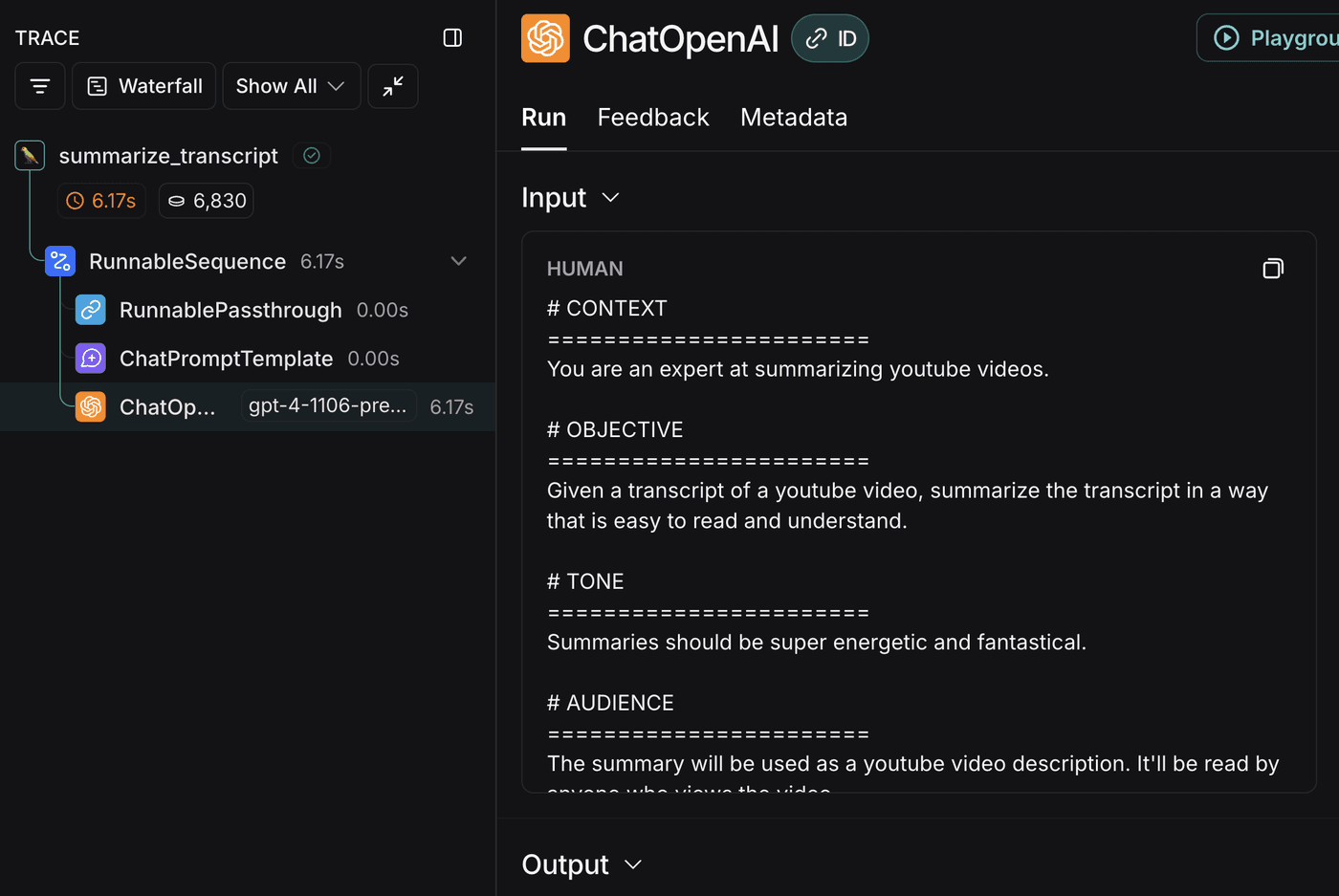
Each of the steps can be examined for inputs and outputs in the LangSmith UI.
Now that we know what a trace looks like, let’s start talking about evaluation!
Evaluation
Evaluation helps you measure if your application is improving. You can:
- Make prompt changes and evaluate them against a dataset.
- Swap out LLMs and compare their performance.
- Compare different dataset runs after making changes.
- Build custom evaluators for your application.
Building Good Datasets
Building a good dataset is one of the more challenging and time consuming tasks when evaluating LLMs. You'll need to carefully consider what aspects you want to evaluate. You can create datasets either through traces or through code. Both approaches are valid, depending on what suits your needs best.
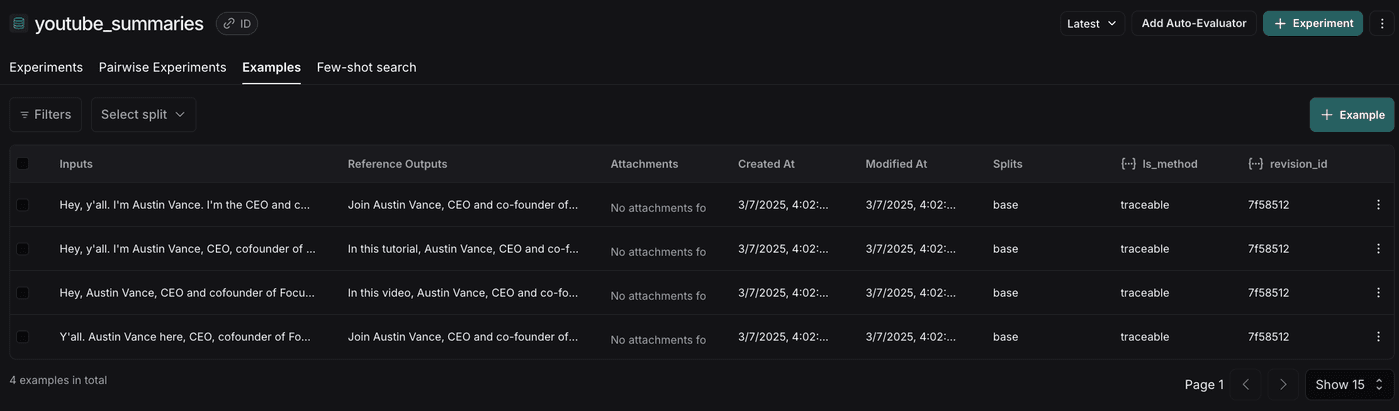
I’ve found building a predefined dataset is most effective when starting a new application. Once you've deployed your RAG chains to a live environment, creating datasets through traces becomes straightforward. This approach lets you identify poor-performing runs and add them to your dataset for targeted improvements.
Building good datasets is hard. Much of creating good RAG chains is wrangling data. The data that comes into and out of your application and the data you evaluate with.
Figure Out What You Want to Evaluate 🤔
Comparing LLM output with expected results is straightforward when dealing with things like structured output. You have a pretty good idea what the results should be, which makes it a bit easier for comparison purposes.
For use cases like chatbots, however, evaluation becomes more complex. You can evaluate things like the sentiment of a response. Or, if you expect the LLM to respond a particular way to a given question or scenario, you can generate what you think would be the correct response and evaluate the LLM’s response against what you expect.
For example, I've worked on an AI Therapist chatbot. While determining evaluation criteria has been challenging, we can assess several key aspects:
- Is this response supportive?
- If someone is having a crisis, do we respond with appropriate therapeutic techniques?
- When a client sets a goal, does the LLM verify that it's their chosen goal and preferred approach? Is the client leading their own goal-setting process rather than being directed by the LLM?
While these evaluation criteria may seem unusual, we can effectively assess them by using LLM-as-judge to analyze our results.
Building a Dataset with Code
Below we see a dataset about basic science questions we can use to test a chatbot tutor. Each question and answer will be logged into the dataset, then you can run an evaluation to see if the answers from your dataset match the ones generated by your rag chain.
from dotenv import load_dotenv
from langsmith import Client
example_inputs = [
("What is the first element in the periodic table?", "Hydrogen"),
("How many bones are in the human body?", "206"),
("What is the biggest planet in our solar system?", "Jupiter"),
("What is a material that will not carry an electrical charge called?", "An insulator"),
]
load_dotenv()
client = Client()
dataset_name = "Basic Science Questions"
dataset = client.create_dataset(
dataset_name=dataset_name, description="Questions and answers about general science.",
)
inputs = [{"question": input_prompt} for input_prompt, _ in example_inputs]
outputs = [{"answer": output_answer} for _, output_answer in example_inputs]
client.create_examples(
inputs=inputs,
outputs=outputs,
dataset_id=dataset.id,
)
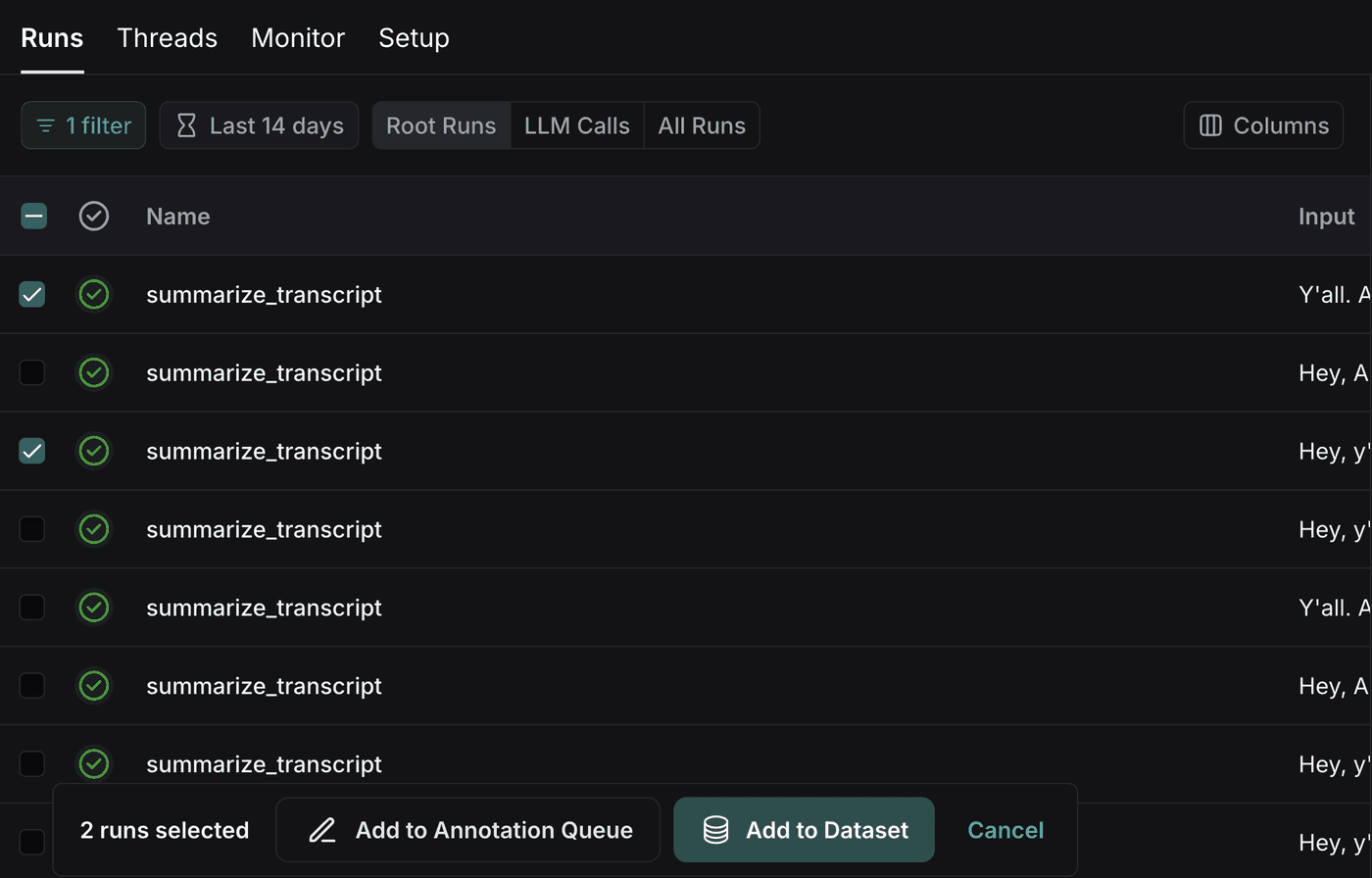
Building a Dataset with Traces
Sometimes using traces is a bit easier if you’re dealing with production data. Find a trace you like, select the check box next to it, and add it to a dataset. From there you can edit the results of the trace to correct them to what you expect them to be, or you can leave the results as is if you like them.
Choose Your Evaluation Methods & Metrics
Now that we’ve built a dataset, we need to choose the right evaluator. There are many different types of evaluators. Choosing the right evaluator for your application is critical to getting good results, though it's one of the more challenging aspects of the evaluation process. Don't worry if your first pass is incorrect; you can always switch evaluators as you refine your approach.
Statistical approaches via code are the best way to evaluate applications when possible. These methods provide the most reliable metrics for measuring prompt improvements. However, in some cases, we need to use an LLM-as-judge for evaluation. How do you test things like sentiment, or if a response is supportive? We have LLMs to help us out!
Types of Evaluators
LangSmith Off the Shelf Evaluators
LangSmith comes with a number of off the shelf evaluators, many of which use LLM-as-judge. These evaluators are straightforward to implement and can assess various aspects of your application, such as:
- The correctness of a response.
- Label outputs with various criteria (e.g. creativity, helpfulness, harmfulness).
- If results are an exact match or use a regex for fuzzy matching.
- Determine if json structured output is valid.
Here is what an off the shelf evaluator looks like for labeled outputs with criteria:
dataset_name = "youtube_summaries"
# We're using an eval llm because
# the built-in evaluator's llm context window is too small.
eval_llm = ChatOpenAI(temperature=0, model="gpt-4o-mini")
criterion = {"creativity": "Is this submission creative and imaginative?"}
criteria_evaluator = LangChainStringEvaluator(
"labeled_criteria",
config={"criteria": criterion, "llm": eval_llm}
)
evaluate(
call_chain, #Calls the method with the llm rag chain
data=dataset_name,
evaluators=[criteria_evaluator]
)
This code demonstrates criteria evaluation, which checks whether the results of a run meet certain creative standards. The evaluate function takes three key parameters: the RAG chain, the target dataset, and the evaluator to be used.
These evaluations use an LLM to judge the results of the output. A couple things happen when you run an evaluator:
- The
call_chainruns multiple times using data from the dataset, and each result is saved as an experiment in LangSmith. Next, the evaluator processes these results. In cases like our example above, it uses an LLM-as-judge to assess whether the output meets your criteria. In other cases, it compares the run results against reference answers stored in your dataset. This process requires LLM calls both for your RAG chain execution and for the evaluation itself.
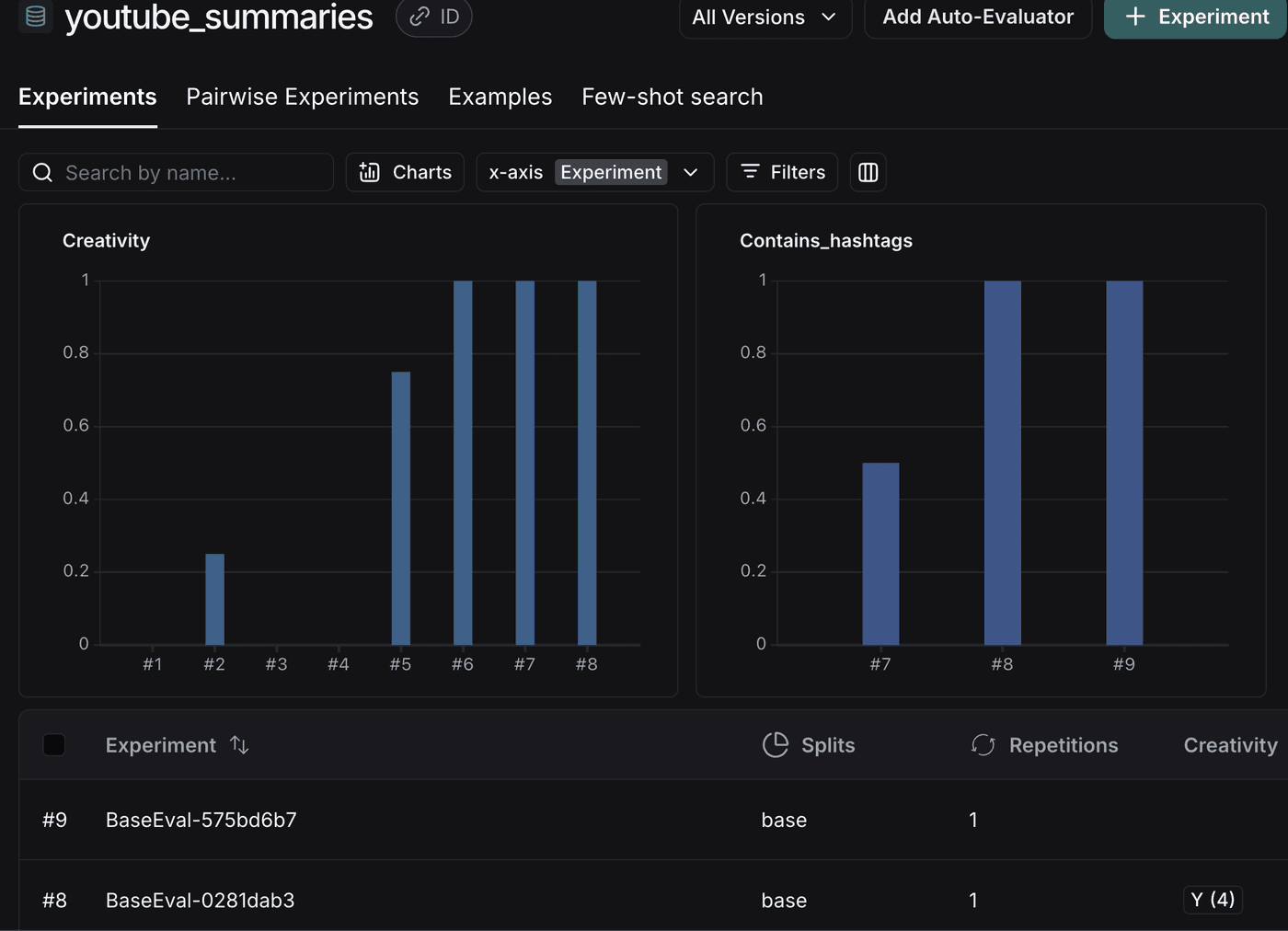
There is a time place for off the shelf evaluators. However, we’ve often found ourselves creating custom evaluations.
Custom Evaluators
While off-the-shelf evaluators are useful, they may not always meet your specific needs. When you need greater control over your metrics and evaluation process, custom evaluators become the better choice.
def contains_hashtags(outputs: str, reference_outputs: str) -> bool:
found_hastags = re.findall(f"#\w+", outputs["output"])
return len(found_hastags) >= 3
evaluate(
call_chain,
data=dataset_name,
evaluators=[contains_hashtags]
)
Custom evaluators offer precise control over your evaluation criteria. Using custom evaluators you can:
- Examine if the output from an LLM meets particular standards (see the above example, does it have at least 3 hashtags).
- Create your own specific metric for scoring outputs (we’ll talk about a good example of this shortly).
- Create your own prompt for scoring and with a mini RAG chain for eval. Essentially, create your own LLM-as-Judge evaluation.
Building custom evaluators is easy! For deterministic results, you can write simple code to check your metrics. This works especially well for structured output where the result is often known. However, for non-deterministic results, like evaluating whether an LLM's response is handling a chat situation appropriately, you'll want to incorporate an LLM into your custom evaluator.
The Importance of Good Metrics
Let's explore what makes effective metrics through a real-world example.

In a recent project, we worked with meeting transcripts to identify speakers. Transcripts were created using AI to process audio from various types of government meetings. The transcripts labeled participants as "SPEAKER 1", "SPEAKER 2", and so on. Since we had a list of meeting attendees, we fed both the transcript and the attendee list into an LLM, using prompt engineering to match speakers with their numbers. The RAG chain output was a JSON map that linked each speaker number to a corresponding name from our meeting participant list.
Initially, we used an LLM-as-judge to evaluate correctness, which proved to be an okay metric. While it scored outputs based on their similarity to the expected dataset values, the scoring was inconsistent. Identical results sometimes received different scores. We also found ourselves spending excessive time in LangSmith manually comparing our run outputs to the expected results.
If you’re experiencing the above scenario… then there’s a pretty good chance you need to rethink your metrics.
The second time we ran evaluations to improve our performance, we came up with a new metric.
$percentCorrect = (numAccurateAnswers)/(numExpectedAnswers + numUnexpectedAnswers)$
So if we have a result
{
"Speaker 1": "Austin",
"Speaker 2": "Shahed",
"Speaker 3": "Candice"
}
And our expected answer is
{
"Speaker 2": "Shahed",
"Speaker 3": "Candice"
}
Our metric will be: Our metric will be: .66 = 2 / (2 + 1)
You can calculate this by comparing the expected result (the example) with your run’s output.
def percentage_correct(run: Run, example: Example) -> dict:
example_outputs = example.outputs
run_outputs = run.outputs
example_size = len(example_outputs)
correct_answers = sum(1 for k, v in example_outputs.items() if k in run_outputs and v == run_outputs[k])
extras = sum(1 for k in run_outputs if k not in example_outputs)
return {
"key": "percentage_correct",
"score": (correct_answers / (example_size + extras)) * 100,
}
test_results = evaluate(
call_chain,
data=data_set_name,
evaluators=[percentage_correct]
)
Now we have a great metric for our structured output! We can instantly assess a run's performance and easily compare different runs by looking at their percentages side by side. This approach proved far more efficient than our previous LLM-as-judge evaluation, which required manual review of results.
With this metric, we could clearly demonstrate that our prompt changes improved accuracy from 85% to 93%. This made it really easy to communicate AI improvements to our stakeholders.
Incorporate LangSmith for the Best RAG Results
We covered how to setup LangSmith, create datasets, run basic evaluations, and how to choose good metrics.
This barely scratches the surface of LangSmith’s capabilities. As LangChain improves their tool offerings, they’ve added more and more functionality to help developers achieve the best results possible for their RAG chains.
It’s an integral tool in Focused’s RAG development process and has led our developers to upskill quickly as they build new LLM applications for clients.