Blog
AI Incident Management Breaks Without a Shared Record
AI incident management works when agents maintain a shared record of evidence, decisions, owners, approvals, and follow-up work, not just plausible root causes.
Jun 26, 2026

How we define “record” for AI incident management is key to everything.
The new AI SRE work is flowing into the incident channel. LangChain introduced Fleet On-Call Copilot that works through traces, code, and runbooks, then drafts an update for human review. PagerDuty says its SRE Agent can start triage from within incident workflows. New Relic describes its SRE Agent as assistive, grounded in live telemetry data, and blocked from making production changes by itself.
Good. Useful. Also incomplete.
The incident does not get fixed because an agent blurts out a plausible root cause. The incident gets fixed because responders agree on what happened, what changed, what has been ruled out, who owns the next step, what has been approved, and what to tell the business. That agreement needs a durable place to live.
The agent that maintains that record of what actually happened is way more valuable than the first clever agent that came up with a plausible root cause for what went wrong.
The market is moving past alert summarization
AI incident management is becoming a named operating surface. NIST held a Workshop on AI Incident Management because AI systems are becoming both targets and sources of risk across critical infrastructure, cybersecurity, and national security. That is the governance side of the phrase. The SRE side is more immediate: agents are being attached to live operational workflows.
Incident.io describes AI SRE agents in reliability tasks (e.g. investigating root cause) that incorporate data from multiple sources of observability data plus reasoning, historical data, and execution of actions. These can be embedded into on-call workflows for real-time troubleshooting and can automate work such as creating a PagerDuty incident. There are two agents within the PagerDuty workflow - SRE Agent which investigates and causes incidents to be opened, and Scribe Agent captures audio, chat, critical decisions, and incident knowledge.
That combination changes the seriousness of the tool. An on-call agent can inspect traces, pull logs, open runbooks, compare recent deploys, and draft a stakeholder update. It can enter the room with better context than a human who just woke up.
The trap is treating that context as a private scratchpad.

Diagnosis is only one incident job
Lorin Hochstein says AI SRE tools are currently used for diagnostic work / for trying to fix problems. That is to say, current AI SRE tools are used for what he calls ‘mitigation work’ as opposed to ‘coordination work’ which is how he characterizes incident management incident management is coordination work. This makes sense to me as in any given incident there is a slice of the system that an AI can learn about and diagnose; but for the AI to be adding value to the human’s work, that part of the system needs to be a subset of the system as a whole. Once the AI is fixed on a portion of the system, it can become fixed in its views in much the same way that any human does, and that which the AI doesn’t know about the system will typically be far greater than that which it does.
That is the part that agent demos underplay. The process of diagnosis is neat and clean to demo. Alert comes in. The on-call reads in telemetry data. The agent has a strong hunch as to the root cause of the problem. The agent makes a recommendation for the fix and it all works out in the end for a nice clean arc that looks good to demo.
Also on the incident management side of the tooling, the messy part of incident response, as opposed to a neat and shiny diagnosis, is coordination of the various teams (e.g. the API team might claim that the issue was caused by the latest deploy; the data team might find a timeout deep in the system that is causing problems; the platform team might report a load spike in a region; etc.). Meanwhile, a customer update needs to go out in 10 minutes. Someone has to decide whether to roll back, disable a feature flag, scale a queue, or continue to watch things. Someone has to document the reasons why the team chose not to take the more scary option (even if it turns out to have worked in the end).
That work is not a side quest. It is the incident.
A private scratch pad in an on call context helps the on call answer a question. It is not of value to the incident record unless the evidence, decisions, ownership, and approvals are written where the rest of the team can read them in real-time.
OpenTelemetry's GenAI work for creating a data plane for such evidence and operational knowledge: the OpenTelemetry blog on GenAI observability. The way model calls, tool invocations, token counts and latency are combined with traces, metrics and events. Note that content capture is off by default, as prompts and tool arguments can contain sensitive information. Such an incident record then has to be evidence-backed but not a secret-spilling chat log.
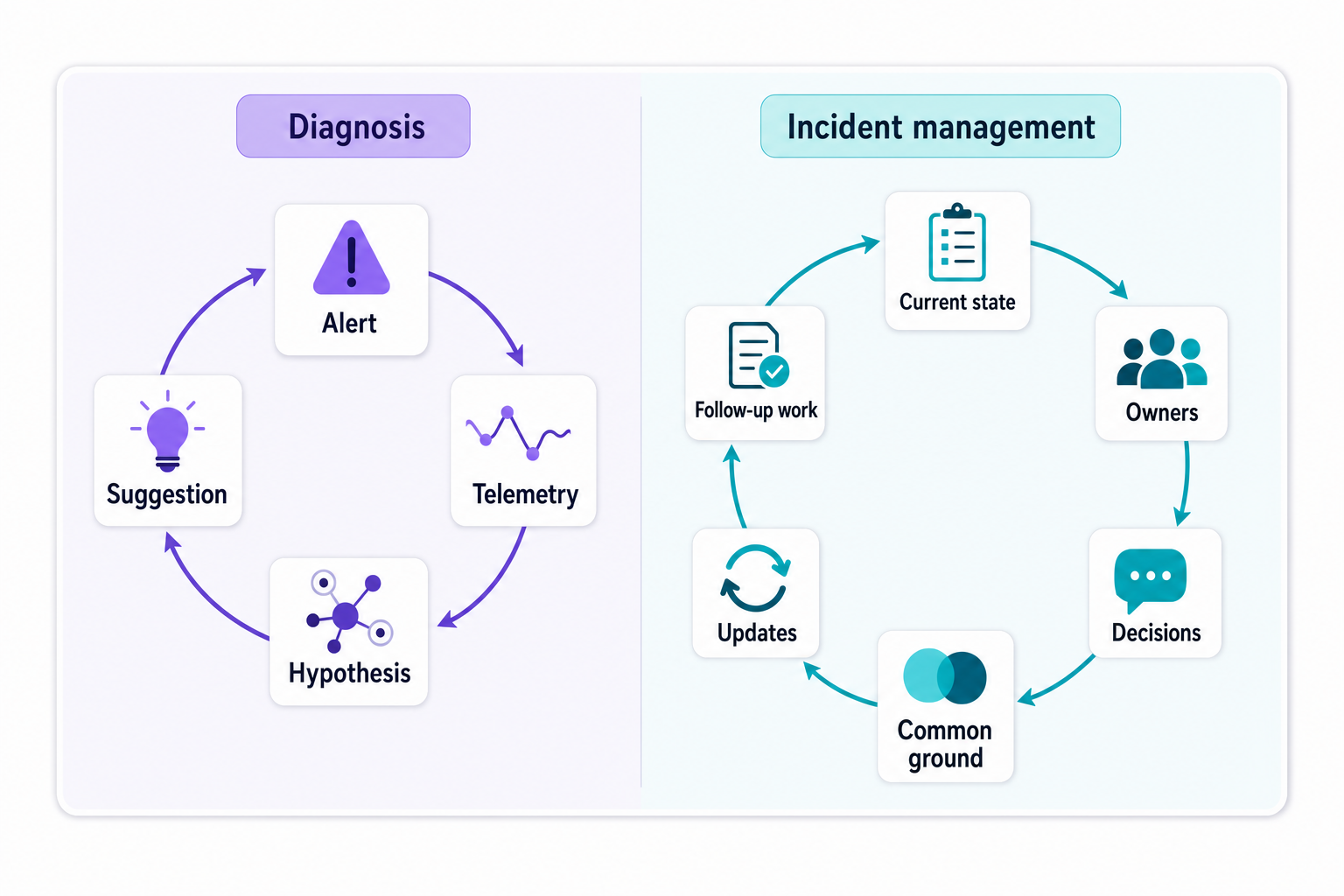
The shared record is the control surface
A useful AI incident record is not a chat log with better vibes. It is a structured operational object.
The trigger such as alert, service, severity, customers affected, deploy time, and suspected blast area starts the record. Evidence follows: traces, logs, metrics, recent changes, runbooks, ownership data, related incidents, and the agent’s own tool calls. That evidence then becomes hypotheses, rejected hypotheses, confidence, gaps, decisions, approvals, owners, current status, and follow-up work.
That shape matters because incident responders do not need another stream to monitor. They need a shared state object that reduces the cost of joining, leaving, handing off, and challenging the current theory.
New responders should easily be able to join an incident and see the current working hypothesis, why the team believes the hypothesis, what they have already ruled out, what action is pending approval, and what customer facing message has already been sent out. If it takes 5 minutes of digging through a teams Slack channel then the team as a whole failed at incident management even if they work out the root cause of the incident.
This is where agent handoffs become runtime state. The handoff of an incident from one agent to another is not simply a handoff of a work item. It is a handoff of context and the handoff of who can take action and approve action. The handoff of an incident from agent A to agent B means that B now owns the database investigation, B now owns the customer communication and the A is watching the traces and is drafting the rollback note for production. Someone has to write this into the record for others to read.
The record also creates the permission boundary. Write access comes later.
As for what they can let the agent do first, the evidence retrieval, writing of updates, comparison of past incidents would all be good starting points. But as for production mutation, that should be behind approvals, for the rollback paths and for change records. (This is similar to how change records are used for agent rollout work before production action. This allows teams to keep the best of autonomy, whilst keeping it from turning into “vibes with credentials” for instance).
In effect that policy is governing at runtime. Thus it should be before the AI SRE tool call. In effect that policy should be showing up while the team is handling the incident. Hence after the incident it should be showing up in the remediation work, i.e. production mutation change records.
The record fights fixation
This is a fundamentally different type of failure to being wrong once during an incident. People are wrong once during incidents all the time, and that is not a problem that can be solved with current technology. This type of failure is when an agent becomes a high-confidence gravity well: the agent finds a plausible cause for an incident, the rest of the response team orbits around that cause, subsequent evidence is interpreted through the lens of that cause, and the agent keeps finding more and more evidence to support the cause because the tools and data that the agent uses to generate hypotheses are shaped by the same cause that the agent believes in already.
Making the shared record force out rejected theories and show supporting and disconfirming evidence for each point of view (even if only provisionally assigned to one theory) will help keep the agent’s biases in check. List out data that is missing and express out current points of contention between team members as well. If one cache theory and another deploy theory (for example) each rely on data from different dashboards, then record both with the owner and list out the next steps to check for each.
These items take minutes to review, and confirm that the team agrees on the basic framework of what they believe is going on. Once the record says what the team believes, why it believes it, what has been ruled out so far, and what the current message to customers is, a responder has enough information to join the conversation already in progress and start to add value.
After the incident has been solved, the record should survive as institutional knowledge. PagerDuty’s Scribe framing matters because transcripts and decisions become reusable operational knowledge, not meeting exhaust. If an incident revealed a missing runbook step, a brittle alert, or a repeated investigation, open a named issue with traces, regression checks, and release evidence, just as with agent failures becoming tickets.
Build the incident record before the incident agent
The right first move is a structured incident record, not an autonomous responder with a dramatic demo.
The first step is a structured record of past and active incidents. Give it clear fields. Let agents read it safely and add to it. Define which evidence gets logged, which secrets stay out, how responder roles move, and how follow-up work gets created after resolution.
Then connect the agent to traces, logs, deploy history, and past incidents. Have it draft the first update with confidence and evidence gaps. Let humans edit, approve, and reject. Measure faster context gathering, cleaner handoffs, better post-incident work, and fewer “why did we roll back?” moments.
The consulting version is painfully practical. A client does not have an AI incident management problem because the model cannot reason. The client has an incident-record problem, an ownership problem, a trace-quality problem, an approval-path problem, and a follow-up-work problem. The model exposes those gaps because it tries to operate across them.
The cleverest AI does not win here. The useful one leaves behind a rich shared record, even when things are rough and the details are getting tiresome.
/Contact Us

Modernize your legacy with Focused
Get in touch