Blog
AI Agent Evaluation Ends Too Early
AI agent evaluation has to keep running through traces, online evaluators, human review, datasets, and redeploy gates after release.
Jun 25, 2026

AI agent evaluation ends too early.
An early score indicates that the harness has been able to execute the few cases imagined by the team while the real evidence will emerge in production.
There is clear evidence that current evaluation methods focus primarily on success. A 2026 review of 15 published benchmarks found that safety and security were included in the scoring of none of the 15 benchmarks; cost efficiency was included in the primary protocol of none of the 15 benchmarks; 13 of the 15 benchmarks relied primarily or entirely on binary success metrics; and none of the 15 benchmarks reached 50% deployment-readiness coverage in the review’s framework.
A benchmark can test for capability to complete a task in general. There is also offline evaluation of a release before it is actually shipped. The real job of evaluation though starts after release.
The evaluation job keeps going.
Benchmarks screen capability
Public benchmarks of agentic behaviors are weak as a basis for deployment, for they test fixed conditions inside a limited scope of possible model-and-harness behavior. They serve as a public capability test, a rough market language, and a way to compare similar designs under similar assumptions. Their numbers have no basis for deployment and must not be confused with indicators of production-readiness.
NVIDIA states that model-capability evaluation and agent evaluation are different things. An agent is an end-to-end system that plans, uses tools, reacts to environment feedback, attains outcomes, and stays within a budget. It shows how an agent can attain the same result through fundamentally different means. In one case, the harness uses the correct tools and properly argues for an answer. In the other case the harness is thrashing about, fabricating facts, burning through tokens, accidentally recovering, etc. All leading to the same correct answer.
It hides failures in the path.
We have previously established that agent benchmark scores measure the harness, and that agent evaluation should steer the harness. This article maps the traces where that steering signal originates after release. Those traces execute the agent with real tools, real permissions, real users, and the tedium that shows up when people repeat steps, get bored, and abandon work in the middle of the process.
The final answer hides broken execution
First, output-level testing has a comforting failure mode. The response is correct. The tone is fine. The task is marked complete. A test runner prints green.
At first glance, evaluating an AI as an agent seems simple. Agents appear to function correctly if they output the right responses to test cases. The problem is that final-output scoring treats the agent as a black box. It does not inspect how the agent uses tools, verifies results, or retrieves information. AWS's Agent-EvalKit writeup points to that failure: an agent can return polished output after a tool failure, or skip verification steps entirely (AWS Machine Learning Blog). The failures of final-output testing show up in tool calls, parameters, observations, retrieved context, retries, and side effects.
Examples get uncomfortable fast: a customer support agent correctly processes a refund, but for the wrong account. A security agent closes the right ticket for a vulnerability, but verified the wrong source. A data agent queries a warehouse to produce a chart that looks correct, but the agent had no business querying that table.

Evaluating an AI as an agent goes beyond output. The dimensions are tool-parameter correctness, grounding, cost, latency, policy, safety, and recovery. Databricks also distinguishes between phases in an AI lifecycle: experimentation, offline testing, production monitoring, and refinement (Databricks). Final-output scoring is not enough; the full trajectory has to be scored.
The eval loop has to stay online
The better loop is boring and continuous.
Develop public benchmarks. Offline evals against a dev dataset prior to release. In prod instrument traces to see: tool calls, arguments, evidence retrieved, intermediate decisions made by the tool, latency to make a decision, cost to take an action, policy checks along the way, and all of the side effects to other tools and systems that are caused by the tool. Use online evaluators for sampling of traces in prod and promote any failed traces into the dataset used for offline evals. Allows reviewers to calibrate the evals to ensure they understand what the evaluator is trying to measure. Subsequent fixes for an issue get re-run through offline evals before redeploy.
Here, evaluation forms a natural service with a lifecycle: development, production deployment, online evaluators, real-time monitoring, and domain-expert calibration over real traces. LangSmith's evaluation workflow starts with dataset creation, then offline experiments, deployment, online evaluators, monitoring, and review (LangSmith evaluation docs). Azure Databricks MLflow 3 says production monitoring can reuse the same judges and scorers used during development, evaluate development and production traces, and collect domain-expert feedback through a review app (Azure Databricks MLflow docs).
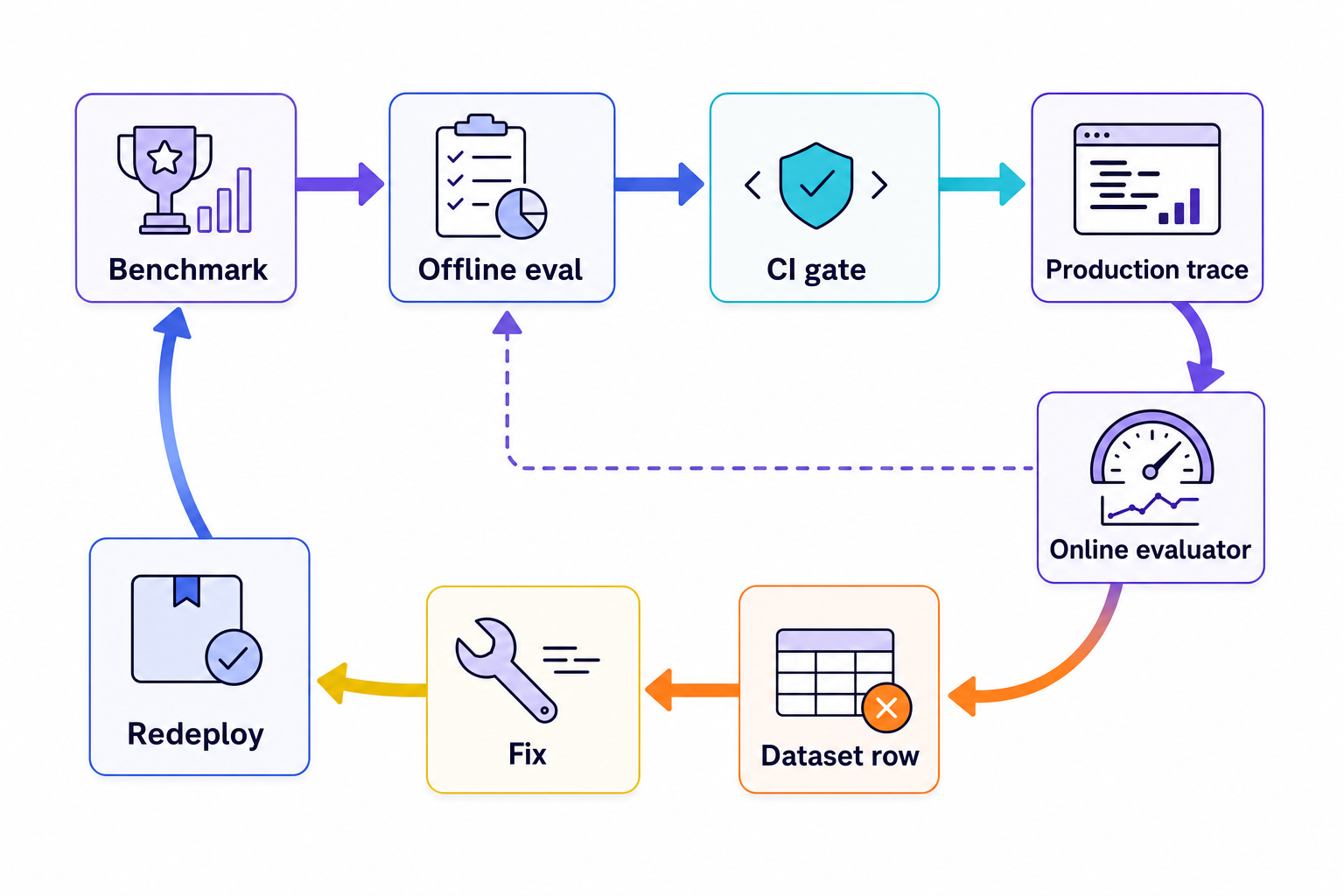
The evaluation system is not a launch report. Rather the evaluation system is the operating loop of the agent in production. The agent’s traces are the evidence the evaluator watches over time and the dataset grows from the production ‘scar tissue’.
Agent accuracy is similarly an ongoing observability problem. Its value is a claim that agent behavior is consistent with the business goal, the tool environment, the policy boundary, and the user’s intent. Those things are dynamic, which is why agent accuracy becomes an observability problem.
Trajectory evals are where the weird failures show up
The deepest agent failures show up as trajectories.
Agent failures follow a path (e.g. calling tools in wrong order, calling correct tool with wrong parameters, etc. retrieving stale policy and then arguing from it beautifully, making a write action before approval, etc. exhausting cost budget through retries, etc. handing off to special agent w/insufficient state, etc.).
For trajectory evaluations in LangSmith, message and tool-call sequence matching can be strict, unordered, subset, or superset. The generated sequence can also be sent to an LLM judge to reason about whether the message and tool-call path was acceptable (LangSmith trajectory eval docs).
Payment authorization before charge. Policy lookup before exception. Account verification before refund. Source retrieval before summary generation. Approval before write. The mundane steps that complete a business task must be specified in the correct order in evaluation.
For LangGraph agents, evaluation pipelines belong close to the graph, with the relevant datasets, evaluators, and regression detection. The graph changes, so the relevant paths through the graph should be named inside the evaluation code.
Human review is calibration, not ceremony
Automated evaluators are off by default until they are properly calibrated. Human reviewers are similarly suspect until they are instrumented. Put both of them in the loop, and they correct each other over time.
Amazon’s evaluation framework includes continuous monitoring and human-in-the-loop validation of final output, as well as the model’s components, behavior, quality, performance, responsibility, and cost (AWS Machine Learning Blog).
Humans are not reviewing models to decide whether to release to production. They are calibrating the scoring loop that will be used on future production traces. The reviewer should see the tool path, evaluator verdict, policy context, side-effect receipt, and proposed row for the eval dataset.
That is why rubrics turn evaluation into runtime QA. A rubric is a reusable set of operating rules for a model. Rubrics are tested against traces, reviewed, challenged, and updated when they fail in production. The vibe of a model cannot block a bad deployment.
An agent eval framework is an operating model
The best AI agent evaluation framework is one that is rooted in ownership.
Who owns the eval dataset for the AI agent evaluation? Who owns the online evaluator? Who reviews failed traces? As traces are collected in production, who decides when a trace in production (as it is collected) becomes a regression case? Who can change the rubric used to score a trace in AI agent evaluation, and who can override the score from the AI agent evaluator (scorer)? Finally, who gets paged if pass rate stays green, but cost per successful task in human-in-the-loop AI (HITL) doubles?
These questions are dull, and that is good. The work of making a system work is dull. The work of making a system trustworthy is dull.
An operating model at full capacity includes a capability screen, a release gate, a production monitor, a review queue, a growing eval dataset, and a redeploy gate. It also keeps a running ledger of changes that affect behavior in production: tool schema, database schema, model version, policy, prompt, rubric, and regression case.
KDD 2026 now has language for evaluation and trustworthiness of agentic AI systems across deployment lifecycle stages, including real-time post-market monitoring, model evolution, production governance, drift detection, anomaly identification, and performance deterioration tracking (KDD Workshop on Evaluation and Trustworthiness of Agentic AI). Systems that keep acting after release get evaluated too late when evaluation stops at launch.
Keep the loop running
According to the State of Agent Engineering 2026 survey, 57.3% of respondents already run AI agents in production. Quality is the biggest challenge for roughly one third of them. Meanwhile, 88.6% already adopted observability, but only 51.7% adopted evals (State of Agent Engineering). There is a big gap between trace storage and effective evaluation.
That gap will hurt.
Trace storage without evaluation is a search problem. Offline evaluation that is not linked to running production traces is theater. Vendor-by-vendor benchmarking brings slides. Human review without a reusable rubric is memory, not evaluation.
Make agent evaluation actually useful. Capture the trajectory. Score the agent’s behavior along a path. Sample from production traces. Use failure cases to augment the evaluation dataset. Have human reviewers calibrate the scoring loop. Use review evidence to block the next deploy when the agent starts to drift off track.
AI agent evaluation ends too early when the last step of evaluation is a score.
The last step should be the next trace.
/Contact Us

Modernize your legacy with Focused
Get in touch