Use Cases
Evaluation Pipelines for LangGraph Agents
Build evaluation pipelines for LangGraph agents using LangSmith. Learn how to create datasets, run LLM-as-judge evals, and detect regressions before they reach production. Ship agent changes with confidence, not guesswork
Apr 8, 2026
You changed a system prompt. It looks better on the three examples you tried. You ship it. Tuesday morning, support tickets spike. The agent is now hallucinating policy details on a class of queries you didn’t test. You revert, but 400 users already got bad answers.
This is not a testing problem. You have unit tests.
This is an evaluation problem.
Traditional tests check “does the code run.” Evals check “is the output good.” For LLM applications, you need a clear verdict: pass or fail. Not a 0.73. Not “mostly correct.” The agent either got the answer right or it didn’t.
Binary evaluators give you that clarity. More importantly, they give your CI pipeline a gate that actually means something.
The cost of not having evals is not “we might ship a bad prompt.” It is that you have no idea if any prompt is good.
LangSmith gives you the pieces: datasets with versioned examples, custom evaluators (deterministic and LLM-as-judge), trajectory evaluation for agent behavior, experiment comparison across runs, and production trace monitoring.
This post builds the whole pipeline, from dataset to CI regression detection.
The Architecture
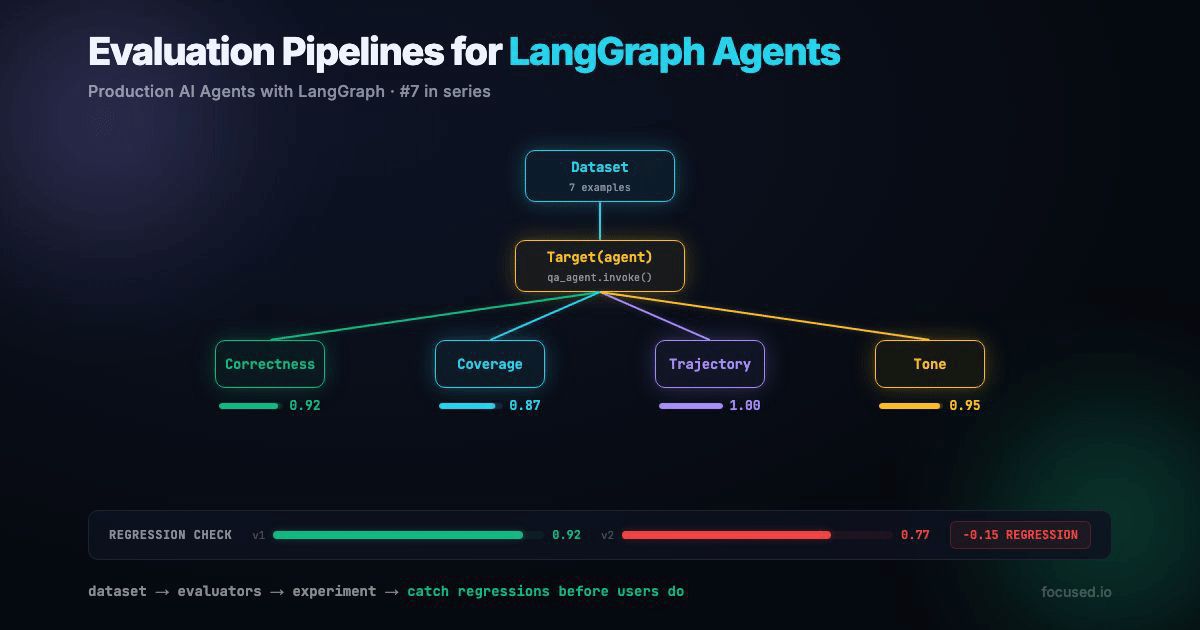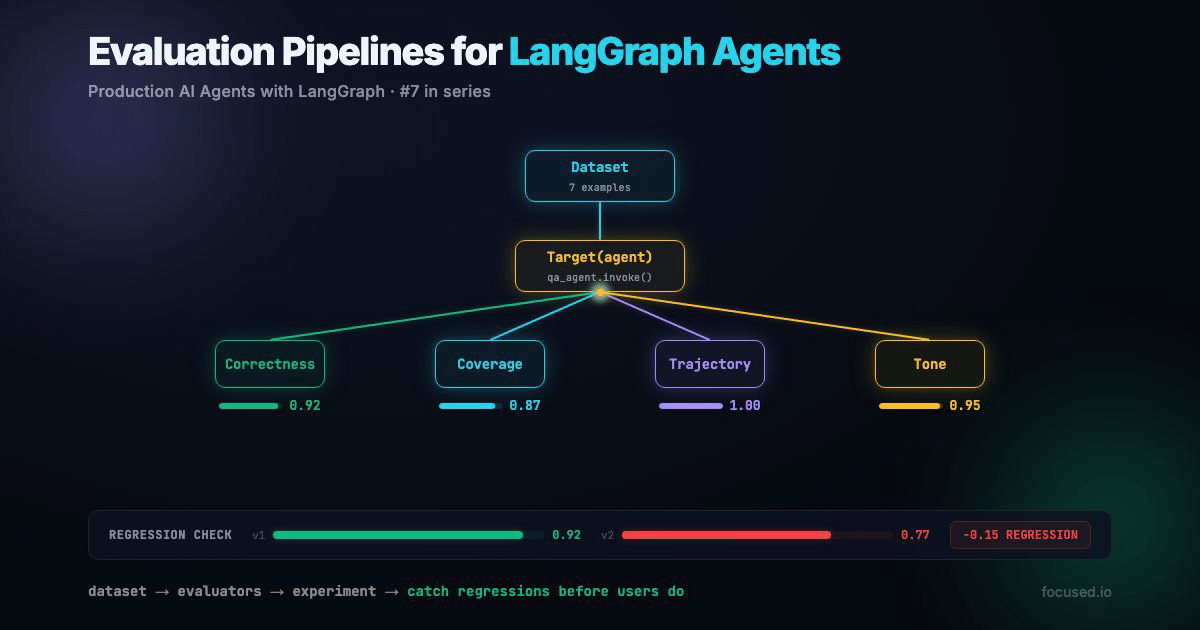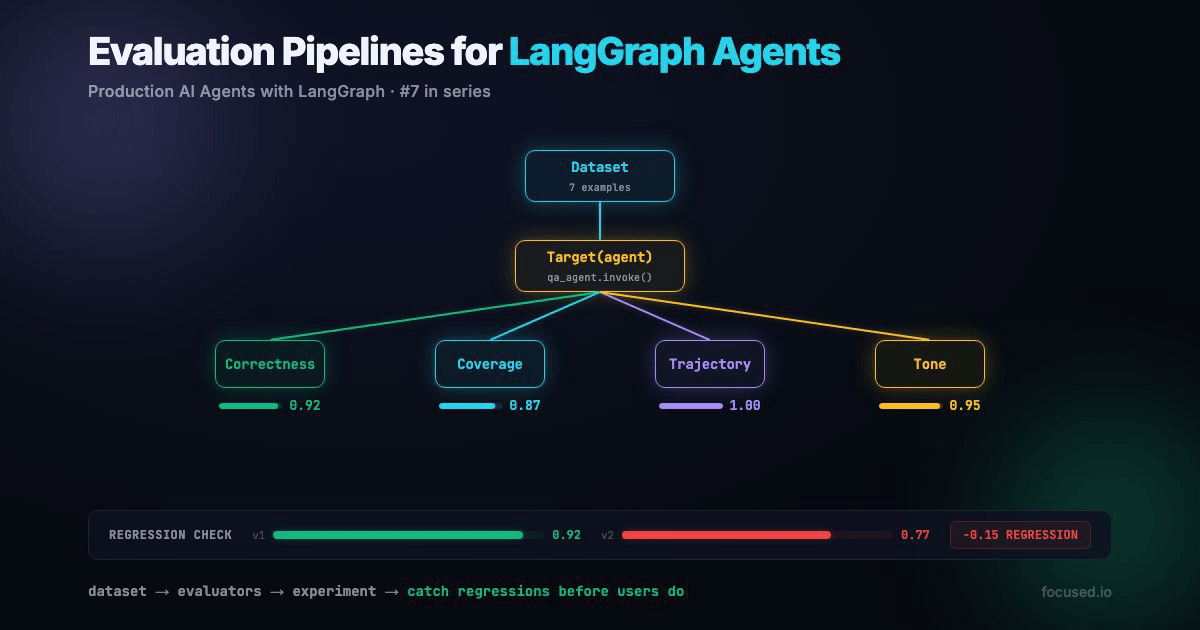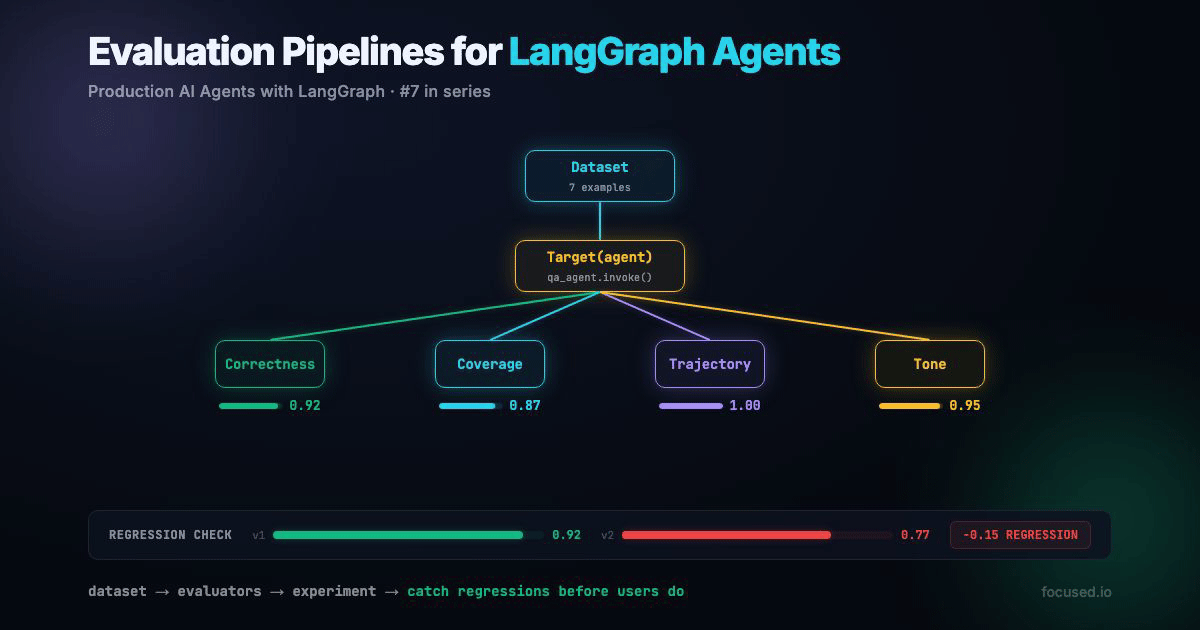
We're building an evaluation pipeline for a Q&A agent. The pipeline covers offline evals (before deploy), online monitoring (after deploy), and regression detection (across deploys).
┌─────────────────────────────────────────────────────────┐
│ OFFLINE EVALS │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │ Dataset │───►│ Target │───►│ Evaluators │ │
│ │ (examples│ │ Function │ │ - Correctness │ │
│ │ + refs) │ │ (agent) │ │ - Completeness │ │
│ └──────────┘ └──────────┘ │ - Trajectory │ │
│ │ - LLM-as-Judge │ │
│ └────────┬─────────┘ │
│ │ │
│ ┌────────▼─────────┐ │
│ │ Experiment │ │
│ │ (versioned scores)│ │
│ └──────────────────┘ │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ ONLINE MONITORING │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │ Prod │───►│ Traces │───►│ Online Evals │ │
│ │ Traffic │ │ (tagged) │ │ (sampling) │ │
│ └──────────┘ └──────────┘ └──────────────────┘ │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ REGRESSION DETECTION │
│ │
│ Experiment v1 scores ◄──── compare ────► v2 scores │
│ │
│ Δ correctness: -0.15 ← REGRESSION DETECTED │
└─────────────────────────────────────────────────────────┘
The Agent Under Test
A Q&A agent that answers questions using a knowledge base. Simple enough to evaluate clearly, complex enough to have real failure modes.
import operator
from typing import Annotated, TypedDict
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import AnyMessage, HumanMessage, SystemMessage
from langchain_core.tools import tool
from langgraph.graph import END, START, StateGraph
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.types import RetryPolicy
from langsmith import traceable
class AgentState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
llm = ChatAnthropic(model="claude-sonnet-4-5-20250929", temperature=0)
@tool
@traceable(name="search_knowledge_base", run_type="tool")
def search_knowledge_base(query: str) -> str:
"""Search the internal knowledge base for relevant information.
Args:
query: The search query to find relevant documents.
"""
knowledge = {
"refund policy": (
"Full refund within 30 days of purchase for unopened items. "
"Opened items eligible for exchange only within 14 days. "
"Digital products are non-refundable after download."
),
"shipping": (
"Standard shipping: 5-7 business days, free over $50. "
"Express shipping: 2-3 business days, $12.99. "
"International shipping: 10-15 business days, $24.99."
),
"warranty": (
"All electronics carry a 1-year manufacturer warranty. "
"Extended warranty available for $49.99 (adds 2 years). "
"Warranty does not cover accidental damage."
),
"hours": (
"Customer support available Monday-Friday 9am-6pm EST. "
"Chat support available 24/7. "
"Phone support: 1-800-555-0123."
),
}
query_lower = query.lower()
for topic, info in knowledge.items():
if topic in query_lower or any(w in query_lower for w in topic.split()):
return f"Knowledge Base [{topic}]: {info}"
return "No relevant results found. Try rephrasing your query."
tools = [search_knowledge_base]
llm_with_tools = llm.bind_tools(tools)
SYSTEM_PROMPT = """\
You are a customer support agent. Answer questions using the knowledge base tool.
Be concise and accurate. If the knowledge base doesn't have the answer, say so —
do not make up information. Always cite the source when using knowledge base results."""
@traceable(name="qa_agent_call", run_type="chain")
def call_agent(state: AgentState) -> dict:
messages = [SystemMessage(content=SYSTEM_PROMPT)] + state["messages"]
response = llm_with_tools.invoke(messages)
return {"messages": [response]}
tool_node = ToolNode(tools, handle_tool_errors=True)
builder = StateGraph(AgentState)
builder.add_node("agent", call_agent, retry=RetryPolicy(max_attempts=3))
builder.add_node("tools", tool_node)
builder.add_edge(START, "agent")
builder.add_conditional_edges("agent", tools_condition)
builder.add_edge("tools", "agent")
qa_agent = builder.compile()
Step 1: Create a Dataset
The dataset is the foundation. Bad examples produce misleading eval scores. Each example has inputs (what goes to the agent) and outputs (the ground truth to evaluate against).
from langsmith import Client
ls_client = Client()
dataset = ls_client.create_dataset(
dataset_name="qa-agent-evals-v1",
description="Q&A agent evaluation dataset covering core support topics",
)
ls_client.create_examples(
dataset_id=dataset.id,
inputs=[
{"question": "What is your refund policy?"},
{"question": "How long does express shipping take?"},
{"question": "Does the warranty cover water damage?"},
{"question": "What are your support hours?"},
{"question": "Can I return a digital download?"},
{"question": "Do you sell gift cards?"},
{"question": "What's the refund window for opened electronics?"},
],
outputs=[
{
"expected_answer": "Full refund within 30 days for unopened items. Opened items eligible for exchange only within 14 days. Digital products are non-refundable after download.",
"expected_tool_calls": ["search_knowledge_base"],
"must_mention": ["30 days", "unopened", "exchange", "14 days"],
},
{
"expected_answer": "Express shipping takes 2-3 business days and costs $12.99.",
"expected_tool_calls": ["search_knowledge_base"],
"must_mention": ["2-3 business days", "12.99"],
},
{
"expected_answer": "The warranty does not cover accidental damage, including water damage.",
"expected_tool_calls": ["search_knowledge_base"],
"must_mention": ["does not cover", "accidental damage"],
},
{
"expected_answer": "Customer support is available Monday-Friday 9am-6pm EST. Chat support is available 24/7.",
"expected_tool_calls": ["search_knowledge_base"],
"must_mention": ["Monday-Friday", "9am-6pm", "24/7"],
},
{
"expected_answer": "Digital products are non-refundable after download.",
"expected_tool_calls": ["search_knowledge_base"],
"must_mention": ["digital", "non-refundable"],
},
{
"expected_answer": "I don't have information about gift cards in the knowledge base.",
"expected_tool_calls": ["search_knowledge_base"],
"must_mention": [],
"expects_no_answer": True,
},
{
"expected_answer": "Opened items are eligible for exchange only within 14 days.",
"expected_tool_calls": ["search_knowledge_base"],
"must_mention": ["exchange", "14 days"],
},
],
)
Seven examples is a starting point, not a finish line. In production, you need 50-100 examples covering happy paths, edge cases, and adversarial inputs. But starting with seven well-chosen examples that cover your core failure modes is better than starting with zero.
Step 2: Build LangSmith Evaluation Evaluators
Three layers of evaluation: deterministic checks (fast, cheap, reliable), LLM-as-judge (flexible, handles nuance), and trajectory evaluation (validates agent behavior, not just output).
Deterministic Evaluators
from langsmith import traceable
@traceable(name="eval_keyword_coverage", run_type="chain")
def keyword_coverage(inputs: dict, outputs: dict, reference_outputs: dict) -> dict:
"""Pass if the response mentions ALL required keywords. Fail if any are missing."""
response = outputs.get("response", "").lower()
must_mention = reference_outputs.get("must_mention", [])
if not must_mention:
return {"key": "keyword_coverage", "score": True}
hits = sum(1 for term in must_mention if term.lower() in response)
return {"key": "keyword_coverage", "score": hits == len(must_mention)}
@traceable(name="eval_tool_usage", run_type="chain")
def tool_usage(inputs: dict, outputs: dict, reference_outputs: dict) -> dict:
"""Pass if the agent called all expected tools. Fail if any are missing."""
messages = outputs.get("messages", [])
expected_tools = set(reference_outputs.get("expected_tool_calls", []))
actual_tools = set()
for msg in messages:
for tc in getattr(msg, "tool_calls", []):
actual_tools.add(tc["name"])
if not expected_tools:
return {"key": "tool_usage", "score": True}
return {"key": "tool_usage", "score": expected_tools.issubset(actual_tools)}
@traceable(name="eval_no_hallucination_on_missing", run_type="chain")
def no_hallucination_on_missing(
inputs: dict, outputs: dict, reference_outputs: dict
) -> dict:
"""When the KB has no answer, pass if the agent admits it. Fail if it fabricates."""
if not reference_outputs.get("expects_no_answer", False):
return {"key": "no_hallucination", "score": True}
response = outputs.get("response", "").lower()
hedging_phrases = [
"don't have information",
"no information",
"not available",
"cannot find",
"no relevant results",
"i don't have",
"not in the knowledge base",
"i'm not sure",
]
hedged = any(phrase in response for phrase in hedging_phrases)
return {"key": "no_hallucination", "score": hedged}
Why pass/fail instead of continuous scores? You don't ship code when 73% of your unit tests "mostly pass." When keyword_coverage fails, you know exactly what happened: the agent missed a required term. A score of 0.75 tells you something is partially wrong, but you still have to go figure out what. And binary evaluators don't suffer from judge variance — the same input produces the same verdict every time.
from openevals.llm import create_llm_as_judge
CORRECTNESS_PROMPT = """\
You are evaluating a customer support agent's response.
Customer question: {inputs[question]}
Agent response: {outputs[response]}
Expected answer: {reference_outputs[expected_answer]}
Determine whether the agent's response is correct.
A response is CORRECT if it:
- Contains the key factual claims from the expected answer
- Does not contradict the expected answer
- Does not fabricate information beyond what the knowledge base provides
A response is INCORRECT if it:
- Misses critical factual information from the expected answer
- States anything that contradicts the expected answer
- Invents details not present in the knowledge base
Return ONLY: {{"score": true}} or {{"score": false}}
with a "reasoning" field explaining your verdict."""
correctness_judge = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
model="anthropic:claude-sonnet-4-5-20250929",
feedback_key="correctness",
continuous=False,
)
TONE_PROMPT = """\
You are evaluating the tone and professionalism of a customer support agent.
Customer question: {inputs[question]}
Agent response: {outputs[response]}
Determine whether the agent's tone is ACCEPTABLE or UNACCEPTABLE.
ACCEPTABLE tone: professional, helpful, concise, empathetic, and action-oriented.
UNACCEPTABLE tone: condescending, rude, excessively verbose, robotic, dismissive,
or inappropriately casual for a support context.
Return ONLY: {{"score": true}} or {{"score": false}}
with a "reasoning" field explaining your verdict."""
tone_judge = create_llm_as_judge(
prompt=TONE_PROMPT,
model="anthropic:claude-sonnet-4-5-20250929",
feedback_key="tone",
continuous=False,
)
Binary judges are more reliable than continuous ones. Ask a model to rate something 0.0-1.0 and you'll get different scores on every run. Ask it "correct or incorrect?" and you'll get the same answer 95%+ of the time. The judge isn't deciding how correct, it's deciding whether the response meets a bar. Easier task, more consistent results, fewer false signals in CI.
Trajectory Evaluator
Trajectory evaluation checks not just what the agent said, but how it got there. Did it call the right tools? Did it call them in a reasonable order? Did it over-call or under-call?
from agentevals.trajectory.llm import create_trajectory_llm_as_judge
TRAJECTORY_PROMPT = """\
You are evaluating whether an AI agent took a reasonable path to answer a question.
The agent has access to a knowledge base search tool.
Evaluate the agent's trajectory (sequence of actions and messages):
{outputs}
A trajectory PASSES if:
- The agent called the appropriate tool(s) for the question
- The agent did not make unnecessary or redundant tool calls
- The agent used tool results to formulate its response
- The agent did not ignore relevant tool results
A trajectory FAILS if:
- The agent skipped tool calls and answered from its own knowledge
- The agent made excessive redundant calls (more than 2 calls for a simple question)
- The agent ignored tool results and fabricated an answer
- The agent called completely irrelevant tools
Return ONLY: {{"score": true}} or {{"score": false}}
with a "reasoning" field explaining your verdict."""
trajectory_judge = create_trajectory_llm_as_judge(
model="anthropic:claude-sonnet-4-5-20250929",
prompt=TRAJECTORY_PROMPT,
)
@traceable(name="eval_trajectory", run_type="chain")
def trajectory_eval(inputs: dict, outputs: dict, reference_outputs: dict) -> dict:
"""Pass if the agent's tool-calling trajectory was reasonable. Fail otherwise."""
messages = outputs.get("messages", [])
if not messages:
return {"key": "trajectory", "score": False}
result = trajectory_judge(outputs=messages)
return {
"key": "trajectory",
"score": bool(result.get("score")),
}
Step 3: Run the Evaluation
Wire the target function and evaluators into evaluate(). The target function takes dataset inputs, runs the agent, and returns a dict with the keys your evaluators expect.
from langchain_core.messages import HumanMessage
from langsmith import evaluate
@traceable(name="qa_eval_target", run_type="chain")
def target(inputs: dict) -> dict:
result = qa_agent.invoke({
"messages": [HumanMessage(content=inputs["question"])]
})
return {
"response": result["messages"][-1].content,
"messages": result["messages"],
}
results = evaluate(
target,
data="qa-agent-evals-v1",
evaluators=[
correctness_judge,
tone_judge,
keyword_coverage,
tool_usage,
no_hallucination_on_missing,
trajectory_eval,
],
experiment_prefix="qa-agent-v1",
max_concurrency=4,
)
This creates an experiment in LangSmith, a versioned snapshot of your agent's performance. The result is a pass rate per evaluator: "correctness: 6/7 passed, tool_usage: 7/7 passed, keyword_coverage: 5/7 passed." Every future eval run with a different experiment_prefix becomes a comparable data point.
Step 4: AI Agent Testing with Regression Detection
The power of experiments is comparison. When you change a prompt, model, or tool, run the same eval suite and compare pass rates.
@traceable(name="compare_experiments", run_type="chain")
def compare_experiments(
baseline_prefix: str,
candidate_prefix: str,
regression_threshold: float = 0.10,
) -> dict:
"""Compare two experiment runs and flag regressions in pass rates."""
experiments = list(
ls_client.list_projects(
project_ids=None,
reference_dataset_name="qa-agent-evals-v1",
)
)
baseline = None
candidate = None
for exp in experiments:
if exp.name.startswith(baseline_prefix):
baseline = exp
if exp.name.startswith(candidate_prefix):
candidate = exp
if not baseline or not candidate:
return {"error": "Could not find both experiments"}
baseline_results = list(ls_client.get_test_results(project_id=baseline.id))
candidate_results = list(ls_client.get_test_results(project_id=candidate.id))
def compute_pass_rates(results: list) -> dict:
counts = {}
for r in results:
for key, val in r.get("feedback", {}).items():
counts.setdefault(key, {"passed": 0, "total": 0})
counts[key]["total"] += 1
if val:
counts[key]["passed"] += 1
return {
k: v["passed"] / v["total"] if v["total"] > 0 else 0.0
for k, v in counts.items()
}
baseline_rates = compute_pass_rates(baseline_results)
candidate_rates = compute_pass_rates(candidate_results)
regressions = []
for key in baseline_rates:
if key in candidate_rates:
delta = candidate_rates[key] - baseline_rates[key]
if delta < -regression_threshold:
regressions.append({
"metric": key,
"baseline_pass_rate": round(baseline_rates[key], 3),
"candidate_pass_rate": round(candidate_rates[key], 3),
"delta": round(delta, 3),
})
return {
"regressions": regressions,
"passed": len(regressions) == 0,
"baseline_rates": {k: round(v, 3) for k, v in baseline_rates.items()},
"candidate_rates": {k: round(v, 3) for k, v in candidate_rates.items()},
}
In practice, you run this in CI. A prompt change creates a new experiment, the comparison script checks for regressions, and the PR is blocked if any evaluator's pass rate drops more than 10%. This is the single most valuable thing you can build with LangSmith — the rest is instrumentation. The regression threshold is 10%, not 5%, because pass/fail metrics move in discrete jumps. On a 7-example dataset, one additional failure drops your pass rate by ~14%. On a 50-example dataset, you can tighten the threshold to 5%. Scale the threshold to your dataset size.
Step 5: Production Monitoring
Offline evals catch regressions before deploy. Online monitoring catches drift after deploy — the slow degradation that happens when user behavior shifts, knowledge bases get stale, or upstream APIs change.
from langsmith import tracing_context
def handle_user_query(question: str, user_id: str, channel: str) -> str:
"""Production entry point with trace tagging."""
with tracing_context(
metadata={
"user_id": user_id,
"channel": channel,
"agent_version": "v2.1",
"prompt_version": "2025-02-01",
},
tags=["production", channel],
):
result = qa_agent.invoke({
"messages": [HumanMessage(content=question)]
})
return result["messages"][-1].content
Tag every production trace with the agent version and prompt version. When you deploy a new version, you can filter traces by version and compare pass rates across versions — with real user traffic, not synthetic examples. The monitoring loop:
- Tag all production traces with version metadata
- Configure LangSmith online evaluators to sample 10-20% of traces
- Dashboard alerts on pass rate drops by version
- When a drop is detected, pull the failing traces, add them to your offline dataset, and fix
Production Failures
These are the eval-specific failure modes that surface once you're running evals in CI and production.
1. Flaky LLM-as-Judge Verdicts. The same input/output pair passes on one run and fails on the next. The judge model is non-deterministic, and your eval is measuring judge variance, not agent quality. Fix: set temperature=0 on the judge model, make your pass/fail criteria as specific as possible (list exactly what constitutes a pass), and run each evaluation 3 times with a majority-vote. If the same example flips verdict more than 10% of the time, your criteria need to be sharper. Binary verdicts are already far more stable than continuous scores, but ambiguous criteria still cause flakiness.
2. Eval Gaming. You optimize the prompt to pass the eval dataset. The pass rate goes up. User satisfaction doesn't. Your dataset is too narrow, the agent learned your test distribution, not the actual problem. Fix: rotate examples into and out of the eval set quarterly. Pull 10% of examples from production traces each month. Never let the eval set become stale.
3. Judge Model Disagreement. You switch the judge from Claude to GPT and pass rates shift by 20%. The evaluator is measuring model preference, not quality. Fix: calibrate your judge against human ratings. Run 50 examples through both the judge and a human annotator. If they disagree on more than 10% of verdicts, your judge criteria need work. openevals provides pre-calibrated prompts as a starting point.
4. Dataset Drift. Your eval dataset was created six months ago. The product has changed, new policies, new features, different user behavior. The evals are passing but they're testing scenarios that no longer matter, while ignoring scenarios that do. Fix: timestamp your examples. Review the dataset monthly. Add production failure cases as they occur. Delete examples for deprecated features.
5. Trajectory Eval False Positives. The trajectory judge says the agent's path was "reasonable" even when the agent called the wrong tool first and then self-corrected. Self-correction is fine in production but expensive, it adds latency and cost. Fix: add a separate tool_call_count evaluator that fails trajectories with more than N tool calls. Combine the trajectory pass/fail with an efficiency gate.
@traceable(name="eval_tool_call_efficiency", run_type="chain")
def tool_call_efficiency(
inputs: dict, outputs: dict, reference_outputs: dict
) -> dict:
"""Fail if the agent made more than 3 tool calls for a single question."""
messages = outputs.get("messages", [])
tool_call_count = sum(
len(getattr(msg, "tool_calls", []))
for msg in messages
)
return {"key": "tool_call_efficiency", "score": tool_call_count <= 3}
Observability
Every evaluator is @traceable, which means your evals themselves are traced in LangSmith. This matters more than you think. When an evaluator produces a surprising verdict, you can inspect exactly what it saw and why it ruled that way.
from langsmith import tracing_context
with tracing_context(
metadata={"eval_run": "qa-agent-v2", "trigger": "ci"},
tags=["evaluation", "ci"],
):
results = evaluate(
target,
data="qa-agent-evals-v1",
evaluators=[
correctness_judge,
tone_judge,
keyword_coverage,
tool_usage,
no_hallucination_on_missing,
trajectory_eval,
tool_call_efficiency,
],
experiment_prefix="qa-agent-v2",
max_concurrency=4,
)
What to watch:
- Correctness pass rate. This is your north star. If it drops, the agent is giving wrong answers. Every other metric is secondary.
- Tool usage pass rate. If this drops, the agent stopped using the knowledge base — probably a prompt regression that caused it to answer from parametric memory.
- No-hallucination pass rate. If this drops, the agent is making up answers when it should be admitting ignorance. This is the most dangerous regression and the one most likely to slip through manual review.
- Failing examples across runs. Track which specific examples fail consistently. These are your hardest cases — either improve the agent to handle them or accept them as known limitations and document them.
Evals
This section is the article, but here's the condensed eval suite for quick reference — the minimum viable pipeline you should have before shipping any agent.
from langsmith import Client, evaluate
from openevals.llm import create_llm_as_judge
ls_client = Client()
QUALITY_PROMPT = """\
Question: {inputs[question]}
Response: {outputs[response]}
Expected: {reference_outputs[expected_answer]}
Does the response correctly and completely answer the question
based on the expected answer?
PASS if the response contains all key facts from the expected answer
and does not contradict it.
FAIL if the response misses critical information, contradicts the
expected answer, or fabricates details.
Return ONLY: {{"score": true}} or {{"score": false}}
with a "reasoning" field."""
quality_judge = create_llm_as_judge(
prompt=QUALITY_PROMPT,
model="anthropic:claude-sonnet-4-5-20250929",
feedback_key="quality",
continuous=False,
)
def coverage(inputs: dict, outputs: dict, reference_outputs: dict) -> dict:
"""Pass if ALL required terms are present. Fail if any are missing."""
text = outputs.get("response", "").lower()
must_mention = reference_outputs.get("must_mention", [])
if not must_mention:
return {"key": "coverage", "score": True}
all_present = all(t.lower() in text for t in must_mention)
return {"key": "coverage", "score": all_present}
def response_length(inputs: dict, outputs: dict, reference_outputs: dict) -> dict:
"""Fail if the response is too short to be useful or excessively long."""
response = outputs.get("response", "")
word_count = len(response.split())
return {"key": "response_length", "score": 10 <= word_count <= 500}
def target(inputs: dict) -> dict:
result = qa_agent.invoke({
"messages": [HumanMessage(content=inputs["question"])]
})
return {
"response": result["messages"][-1].content,
"messages": result["messages"],
}
results = evaluate(
target,
data="qa-agent-evals-v1",
evaluators=[quality_judge, coverage, response_length],
experiment_prefix="qa-agent-quick-check",
max_concurrency=4,
)
When to Use This
Build a full eval pipeline when:
- You're shipping prompt changes more than once a month
- More than one person works on the agent
- The agent handles queries where wrong answers have consequences (policy, pricing, compliance)
- You need to compare model versions (Claude vs GPT, Sonnet vs Haiku)
- You're running A/B tests on agent behavior
Start with just deterministic evals when:
- The agent is in early development and schemas are changing weekly
- You have fewer than 5 test cases
- The output format is structured (JSON extraction) and correctness is binary
Skip evals when:
- The application is a prototype that won't see real users
- You're the only user and you'll notice regressions immediately
The Bottom Line
Evals are not a nice-to-have. They're the difference between "I think the prompt is better" and "I know the prompt is better, and here are the pass rates." Dataset, evaluators, experiment, comparison. Four components. ~20 lines per evaluator. The payoff is catching every regression before your users do. Pass/fail is the right default. Continuous scores feel more sophisticated, but they create ambiguity — is 0.72 good? Is a drop from 0.81 to 0.76 a regression or noise? Pass/fail kills the question. Green or red. When you need more nuance, add more evaluators with sharper criteria instead of adding decimal places to existing ones. Start with three: one deterministic keyword check, one LLM-as-judge for correctness, one for tool usage. Run them on every PR that touches agent code. Add trajectory evaluation when your agent has more than two tools. Add production monitoring when you have traffic. And update the dataset — the dataset that stops growing is the one that stops catching bugs.
Technical Resources
LangSmith Evaluation (datasets, evaluators, experiments)
/Contact Us

Modernize your legacy with Focused
Get in touch