Blog
Agent Rubrics Turn Evaluation Into Runtime QA
Agent rubrics move evaluation from offline scoring into runtime QA with verifier loops, criteria ownership, and observable verdicts.
Jun 3, 2026

Agent evaluation has been too detached from the run of the agent.
For production AI agents, we typically score the trace after the fact (i.e. offline). We compare the final answers in a benchmark harness. Sometimes we call in a human reviewer to verify that the agent’s output “smells right”. That gives us decent research notes and nice screenshots for an exec readout, but that does not tell us if the agent is “done” in production.
Runtime QA has to sit inside the agent loop.
LangChain has released RubricMiddleware for Deep Agents. Evaluation of AI agents has focused on the grading of one LLM by another LLM. There is already discourse in this space around judge bias, model drift, scoring methodology, and benchmark theater. Where the evaluation of an AI agent’s performance actually happens is inside the runtime QA harness, i.e. where the agent is put through its paces against specific criteria. This is where RubricMiddleware adds interesting functionality.
It runs before the agent gets to leave.
In traditional eval, agent benchmark scores measure the harness, not just the model. The score of the trace after the fact determines how “good” the deep agent was. By steering the harness, AI agent evaluation affects how a deep agent is used for work. Useful, but incomplete. The runtime definition of done still matters: when is a customer-service agent done with a chat? When is a coding agent done with a coding task? When is a research agent done with a question? The score after the fact only gives an impression of what might happen in production. It does not guarantee anything.
Offline evals do not close the loop
Offline evals still matter. As I wrote before, ai agent evaluation steers the harness. Datasets, trajectories, scorers, and regression suites all end up steering the AI agent system over time. A new prompt, tool, model, memory policy, or AI agent orchestration change gets evaluated, and the team learns whether the system got better or worse over time.
They do not protect the individual run.
The issue is that a customer-service agent’s “evaluation” can say it passed the suite on Tuesday, yet have it botch a live account-change request on Wednesday because it relied on stale order status, unclear account-change policy, or a tool response the dataset missed. A coding agent can pass its benchmark suite, yet hand back a “refactored” codebase that fails the migration test. A research agent can churn out a fluent answer and still miss the citation the downstream workflow required.
The gap is the runtime definition of done.
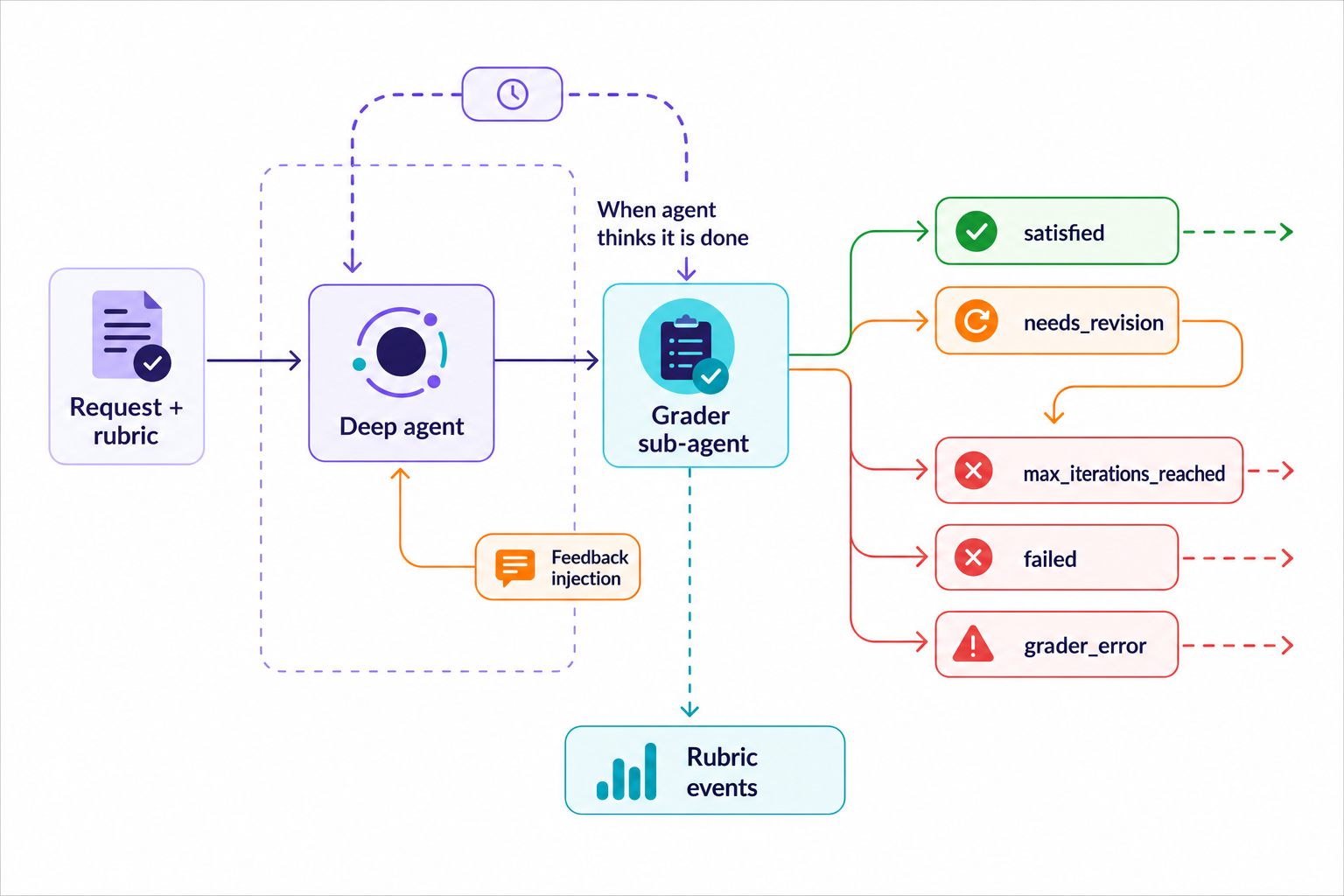
LangChain has described a pattern here in the Deep Agents rubric docs. The basic loop is simple enough: the deep agent arrives at a final-looking output, a grader sub-agent reviews the transcript against the rubric, and each criterion comes back as needs_revision or satisfied. When a criterion needs revision, that feedback gets injected into the next pass. The loop exits when the agent satisfies the rubric, hits the iteration cap, fails at runtime, or the grader fails.
That extends the harness used to evaluate the AI agent to include the criteria used to teach the agent in the harness. The eval harness is extended into the runtime of the AI agent where it can check criteria in the actual traces produced by the agent in real production work.
Rubrics turn done into runtime state
A rubric is valuable in making the word done less squishy.
For a legal research agent, done can mean covered jurisdictions, cited authority for every conclusion, and no cited case outside the relevant date range. For a customer-service agent, it can mean verified account ID, the billing action required by policy, and a clear audit note. For an engineering agent, it can mean passing tests, a diff inside allowed paths, and a migration script that exists.
Yes it is. And that is exactly as it should be. Production QA is typically dull work, boring and thankless, but necessary, so someone has to do it.
The criteria of the rubric can be incorporated into the run of the agent. The grader sub-agent can review the transcript, call tools, and return structured feedback. The transcript can then be forced through another pass because the rubric was not satisfied. This is managed by the middleware and configured through the grader model, system prompt, optional grader tools, iteration cap, and on_evaluation callback. There are also custom stream events for rubric_evaluation_start and rubric_evaluation_end, with the result, explanation, and per-criterion verdicts.
But beyond these basic facts, there is more to the story of observability. Honeycomb has described the need for production telemetry in AI-enabled workflows, and its March release describes AI agents investigating production issues with the same telemetry an SRE uses. Rubric verdicts, including failed criteria, form part of the evidence stream for runtime behavior of an AI-powered workflow.
That is operational evidence, not vibes.
The grader has to be owned
If evaluation simply becomes a quality assurance function then it goes wrong quickly.
That will fail.
When treated as mere quality assurance for deep agents, the grader sub-agent becomes infrastructure with its own model, prompt, tools, timeouts, error modes, and cost profile. It can be too lenient. It can be too strict. It can fail with a false pass. It can also be slow enough to bury the run in retries. Or worse, every hard judgment routes through a frontier model and turns QA for the agent into the new and unforeseen cloud bill.
Another useful point from the LangChain Python reference is that when grader feedback is injected into the conversation, it is tagged as synthetic feedback from rubric_grader. The feedback also contains source metadata, so it is clear that this feedback was generated by a grader and not by the user of the chat. Synthetic QA feedback must be distinguishable from real user input.
This is where ownership shows up.
People misinterpret this pattern. They bolt a grader on a deep agent and suddenly the grader is QA. That fails quickly. The pattern works only if the team has a shared understanding of what the rubric for quality means. Product and domain experts accept the rubric as acceptance criteria for the product. Engineering executes those terms in a loop. QA enforces pass/fail on those terms for the agent in a run. Observability shows the evidence that proves those terms were met.
Verification has a cost curve
On the same day that LangChain published the above piece on using rubrics as QA feedback, it co-published designing efficient verifiers for legal agents with Harvey. This piece is the practical follow-on to that previous post and outlines the key tradeoffs involved in effective verification.
The post discusses verifier cost on Harvey’s Legal Agent Benchmark (LAB). LAB is not a toy for verifying legal agents. It currently consists of 1,250 long-horizon legal tasks across 24 practice areas and 75,000-plus expert-written rubric criteria that a verifier would check against an agent’s output. The initial results are brutal but useful. Under Harvey’s strict all-pass standard, frontier models completed less than 10 percent of tasks end to end, with the top configuration around 50.90 dollars per task and about 22 minutes. This is the kind of task where a false pass would have serious consequences.
A failed criterion can go to review. A criterion that should have failed but passed is worse because it can become client risk.
The verifier-cost post lands on a useful conclusion: per-criterion verification with a frontier model gives a narrow judgment window, but gets expensive fast. Batched verification can bring repeated input-token costs down by about an order of magnitude, but agreement drops. Cheaper open models drop cost again, but the false-pass rate has to be watched as a production risk.
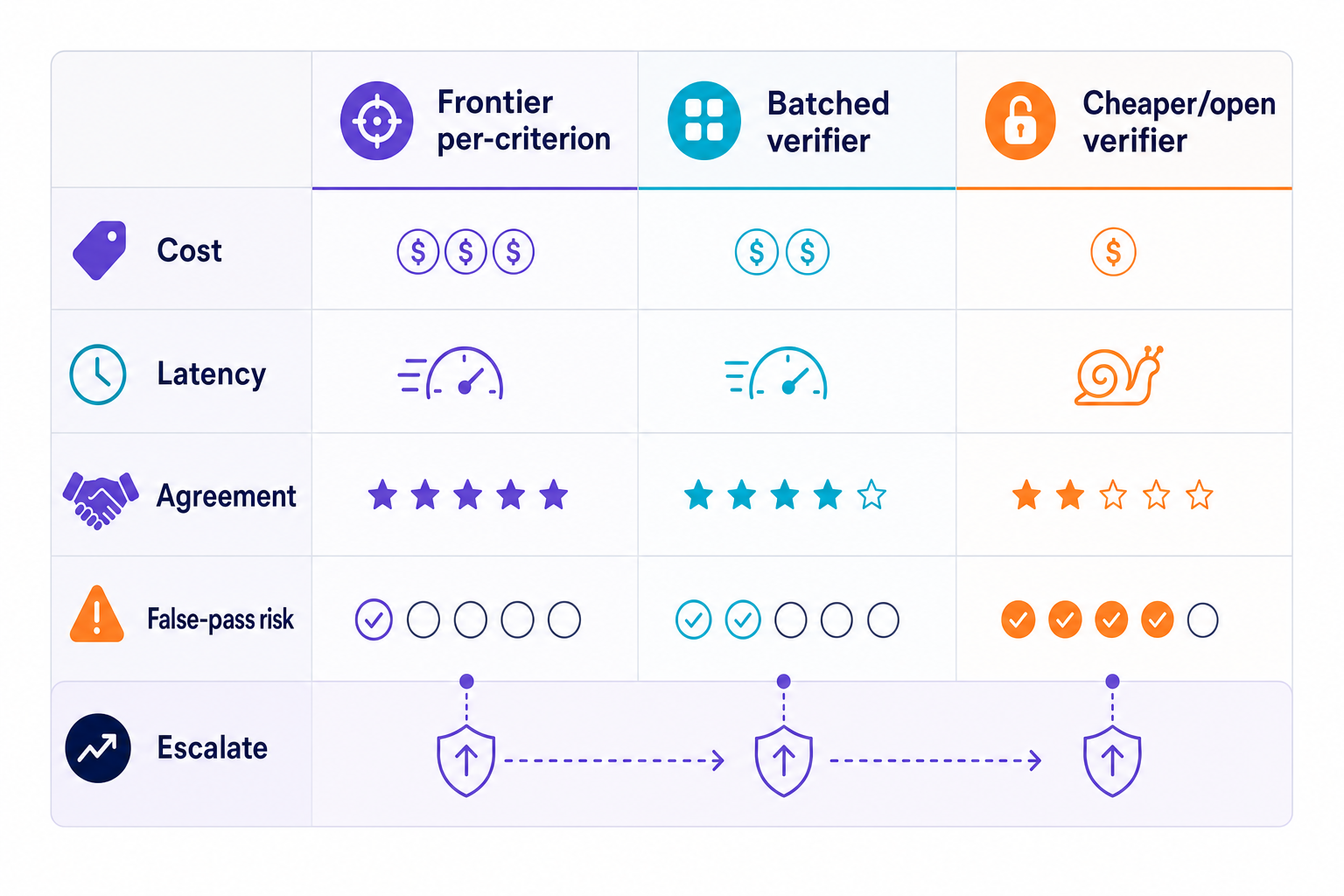
But then buyers feel it. The QA work just described is quite different from calling a frontier verifier on every criterion for every task. The production AI QA work consists of designing a system that can route work to the appropriate type of verification for each criterion, depending on risk. That is model routing applied to verification, with QA policy deciding which verifier belongs on which criterion. So, the system can use a cheap checker for low-risk formatting work, stricter verifier settings for high-risk domain work, and combine tool-generated evidence with human review where the risk deserves it.
The runtime should know the difference.
Failed criteria should become work
A rubric failure is a better incident than a vague agent failure.
First, failing a criterion is better than not having a review process at all. When the agent fails to meet a criterion, the owner can revise it, the reviewer can inspect the failure, the platform can collect data around that failure, and the owner can add tests to verify that the agent meets the criterion in future cases.
I wrote a similar post called Agent Failures Should Open Tickets, where I argued that agent failures should become work in the engineering system instead of vanishing in chat. Rubrics are then the specific acceptance test for a criterion that failed grading in live runs. The work item does not say “agent failed” but instead “rubric criterion 4 failed” after the billing-policy retrieval tool returned stale policy text in later retrieval runs.
That changes the improvement loop.
The team can now see whether errors fall into categories, e.g. lack of context for the agent, bad tools, bad rubric criteria, bad prompts, or verifier drift. The team can cross-reference failures in production against failures in offline eval. The team can make release gates for individual criteria stricter if those errors escape and cause defects in production.
This is also where a rubric becomes the runtime side of change control. A rubric is an acceptance test with a language-model-shaped grader. That does not make it magic. It makes it easier to express criteria that were already implicit in a human review process.
Observability makes rubric QA real
RubricMiddleware exposes an on_evaluation callback as well as stream events. I consider the runtime and QA process around these events the thing that turns a self-correction loop into something testable. The harness is still producing a trace. Runtime acceptance criteria, as expressed by the rubric, should be testable as well. The verifier design and related runtime verification should be exposed like any test case.
A production agent should write out a full runtime trace for every query and emit for every acceptance test, including the rubric ID, all the criterion IDs, the grader model, the final verdict, the full explanation, the number of iterations it took to reach a conclusion, the retry cap, any tool evidence collected during evaluation, the total latency to reach a conclusion, the total cost of the verifier used to reach a conclusion, and the final disposition of the query. The UI should highlight when human feedback was injected into the system. The trace should clearly indicate when feedback was injected. The runtime trace should be distinguishable from human generated messages, such as customer complaints, and the trace from previous runs should be easily comparable to highlight any drift in the verifiers over time. The dashboard should also be able to clearly highlight the point at which a grader, or set of graders used by the system for verification, failed due to lack of proper credentials or a change in validator tools.
That is the work. Boring, specific, necessary.
I find it helpful to read the optimists and the pessimists on AI and arrive at the same point: there is risk here, and there is no natural feedback loop. Charity Majors wrote this week that AI enthusiasts and skeptics are both reacting to real risk, and her line, “There is no natural feedback loop,” is the frame I keep coming back to. Rubrics can become part of that feedback loop if verdicts are exposed, owned, and acted on.
If the loop is invisible, it becomes another agent trick. If the loop is observable, it becomes runtime QA.
Own the criteria before scaling the agent
The hard part is not adding middleware.
It turns out that deciding what done means, and what to do when each type of failure occurs, is hard product and engineering work.
Manual review cannot keep pace with fan-out work across tools, files, and documents. Blind self-correction cannot safely verify that work either. A runtime rubric provides verification before the agent delivers work, while giving the team evidence when the system cannot complete the loop.
The offline harness is separate from runtime QA. Change control is separate from runtime verification and enforcement. In fact, the harness, release process, and runtime rubric form a chain: the harness drives the test runs; the release process gates the new baseline; and the runtime rubric verifies on a per-run basis whether the agent can finish the QA loop for that work item.
Own that boundary.
/Contact Us

Modernize your legacy with Focused
Get in touch