Blog
Agentic AI Architecture Needs Model Routing
Agentic AI architecture needs model routing, telemetry, and policy so production agents can send each workload to the right model instead of one default.
May 6, 2026

Agentic AI architecture is stuck on model loyalty.
The same graph. The same provider. One giant model doing every job because one graph is easier to defend than a routing policy.
I get why people want to pick one model: it makes demos and evaluation and procurement easier, and sometimes debugging only slightly worse. The agent call becomes always the same, the trace becomes always the same, and the team can blame one provider instead of four.
Fine. But production agents do not do one kind of work.
Classify intent. Search. Summarize. Write code. Choose a tool. Check if a tool's result smells wrong. Write a customer-facing answer when something failed. Decide whether approval is required. Wait for something to happen. Retry something that failed. Recover from something gone wrong.
Production agents run a pile of distinct workloads.
Harrison Chase notes that LLMs are getting expensive, and open source models matter for that reason. LangChain is pushing the same direction from a product perspective, noting that Fleet agents no longer have to be constrained by a single model and can instead use multi-model support.
Those are the same production reality arriving through two doors.
The agent architecture must determine which model should perform which work.
The Same Model Everywhere Is an Architecture Smell
This is surprising. Many current agent stacks treat model selection as just another config parameter of the environment, equivalent to tradeoff parameters or batch sizes. Set MODEL=claude-whatever or MODEL=gpt-whatever and deploy the agent.
That's fine for a chatbot, but lazy for an agent.
Agents introduce variance internally. What looks simple to a user becomes retrieval, planning, transformation, checking, execution, generation and scheduling inside the system. Some of these steps need to be deep, some fast, some cheap. Some need a model that is good at generating code, others an open-weight model because the data cannot legally leave the boundary, or because it is simply too expensive to move around the company.
Using the same frontier model across the board is comforting. It also conceals the waste.
Instead of one glaring failure, I get slow, expensive, bureaucratic agent production. A team looks at the dashboard. Cost rises, latency rises, and people say the model is too expensive or the prompts are too long. The architecture is linear and all steps go to one place.
What gets under my skin is the compute monolith. Everywhere else we have learned to separate compute classes properly (queues are not databases, lambdas are not batch workers, CDNs are not origin servers). Then some clever agent comes along and suddenly every cognitive function has to go through the biggest model in the account.
Come on.
Routing Has to Do More Than Fallbacks
Model routing usually enters the conversation through reliability. If OpenAI is down, try Anthropic. If a deployment is overloaded, try another one. If a provider rate-limits, retry somewhere else.
This is important. LiteLLM's router docs explain load balancing, cooldowns, fallbacks, timeouts, retries, and Redis-based production rate limiting. OpenRouter's provider routing docs explain provider ordering, fallbacks, performance, price, and data policy constraints. Boring infrastructure at its best.
But routing cannot stop at uptime.
In a production agent workflow, the router should understand why a task exists. It should see the agent step, the tool context, the risk, latency budget, data boundary and previous run quality. Then it can pick the appropriate model class for the work at hand.
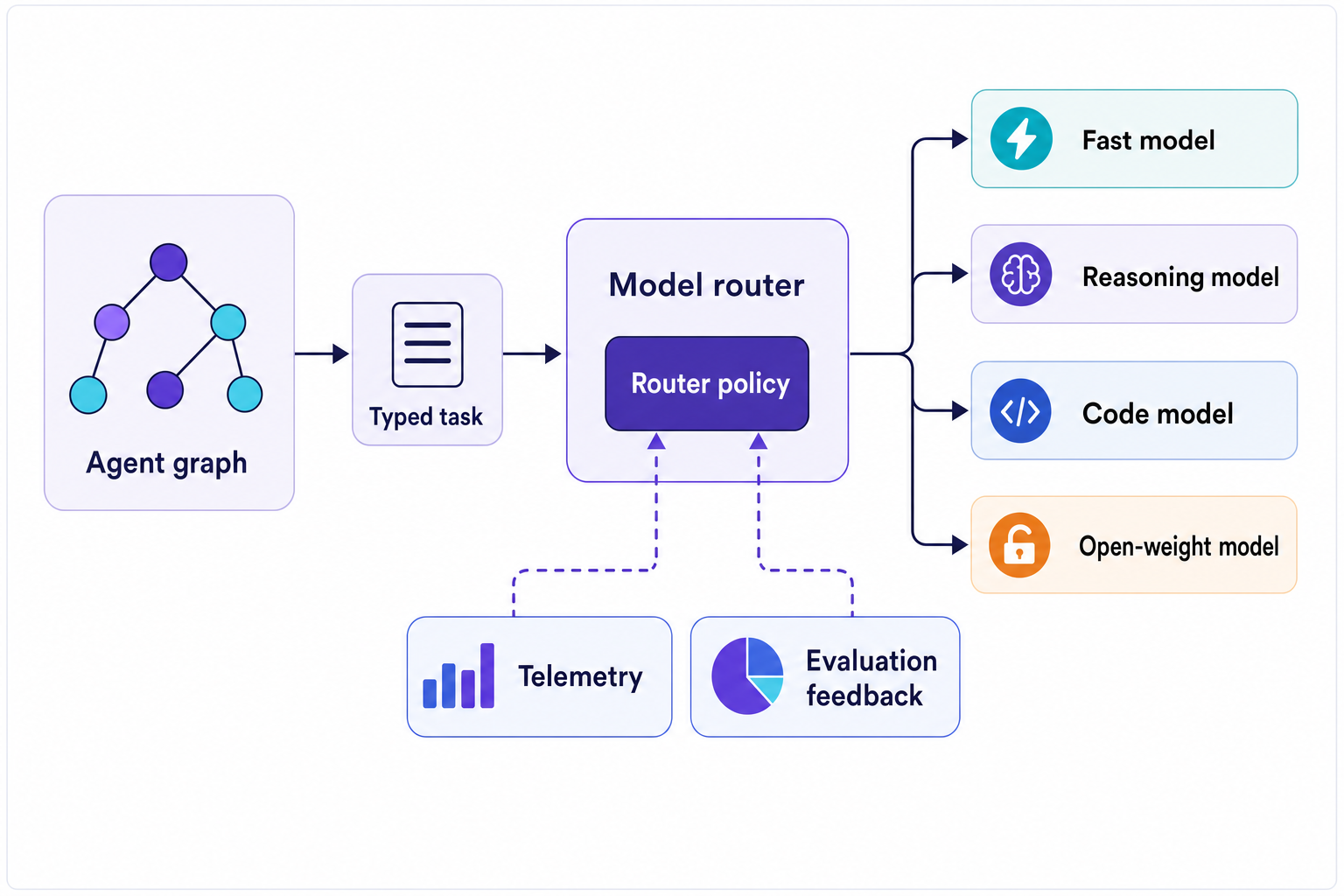
This is where things get more interesting for agentic AI architecture, compared to just building an LLM app. The router turns the agent’s internal structure into an execution policy.
A planner step can go to a reasoning model. A normalization step can go to a fast model. A code-editing subagent can go to a model tuned for code. A bulk summarization step can go to an open-weight model. A regulated data step can stay inside the boundary. A customer-facing final answer can take the slower path because that is where quality matters (since it impacts the customer).
The pattern is already familiar, which is the point. It has the same shape as multi-agent orchestration in LangGraph, but I like it better down at this level. The graph determines what work exists, and the router determines which model class should process that work.
The Router Needs Typed Work
Prompt-based routing is where it all goes wrong.
A team adds "Use the cheaper model when the task is simple." The agent is amiable, but ignores the team's intent at exactly the wrong time. The AI guesses or routes based on whatever words match the current prompt. The result is a vibe with a model attached.
The router needs typed work.
My ideal is for the agent to report task metadata before the model call occurs: task kind, expected output shape, sensitivity of input data, allowed tools, user-facing risk, latency/cost budgets, required capability, and retry posture. I do not need a full taxonomy to start. Most teams can begin with something tiny: classify, retrieve, reason, write, code, act. The key is moving model choice from prose to runtime.
This is a lesson already learned elsewhere in agent architecture. In Developing AI Agency, explicit mechanisms for planning, tools, memory, and verification beat one giant prompt pretending to be architecture. Model selection is another version of this.
The router can start dumb and be a simple lookup table driven by task type. It can be configured to dispatch to the code model for code tasks, the fast model for low-risk summaries, the local model for sensitive data, and the quality model for final text written for specific customers. First, ship that. Verify that it works. Then gradually become less dumb and add more nuance to the router.
The first mistake is expecting the team to find the single best router before shipping anything. The second mistake is letting the model design the router policy inside the same prompt it is supposed to execute.
Observability Makes Routing Honest
A router that does not publish telemetry data becomes an additional place where opinions get hidden.
An engineer's affection for a particular design, the score of a benchmark, and the features listed on a vendor's web page are all useful, but ultimately insufficient. The only relevant test is whether the routing rule improves the production agent's performance on the tasks it actually faces.
This means we need to consider cost, latency, error rate, retry rate, approval rate, human correction rate and eval score when deciding the routing for a request. So these statistics need to attach to the routing decision itself, not just to the trace.
LangSmith's platform language is already pointing in this direction. It treats traces as the record of an agent’s actions and reasoning, and says teams should monitor cost, latency, errors, and qualitative online evals. Fleet's product page puts model choice next to admin controls, observability, approvals, MCP connections, and export via APIs. This is the signal.
Model selection has moved from dropdown aesthetics into operational control. It affects the performance of a wide array of business processes.
Once routing is visible, the discussion shifts. The team can stop arguing over which model is best and start figuring out which route failed: fast model for tool argument generation, reasoning model for eval lift, open-weight model for internal summarization, code model for patch generation.
Those are engineering questions.
The answers need to inform the router policy, or else the agent keeps making yesterday's decisions with today's realities.
Open-Weight Models Are Part of the Architecture
The open-model conversation is often deeply ideological. People tend to think in terms of closed models versus open models, frontier quality versus control, benchmarks, and vibes.
Production is less dramatic.
Open-weight models give teams another execution path. They are useful when the task is bounded, when the data boundary matters, when throughput matters, when the cost curve gets ugly, or when the model only needs to be good enough for an internal step the user never sees.
A frontier connection does not mean every call should route through that location. That misconception is common. Routing makes the difference.
A team can still use a frontier model architecture for the high-risk reasoning step. And yes, the final answer can still go through a strong hosted model. But the retrieval cleanup, first-pass summarization, metadata extraction, and internal critique may not automatically deserve the same spend.
There is no best model for this problem. The more useful question is: Which model owns this step under these constraints?
Interface portability matters for the same reason. LangChain says Deep Agents ships with ACP so the same harness can run across multiple interfaces. The Deep Agents CLI docs show a coding agent with provider credentials, model switching, tools, memory, skills, MCP tools, and LangSmith tracing. The interface can change. The harness can change. The routing policy has to be portable across both.
Model choice that lives in a UI dropdown is prone to drift. Model choice that lives in the agent runtime can be tested, traced, reviewed and rolled back.
Own the Decision Boundary
The old agent stack revolved around a model call. The next one revolves around a decision boundary.
That boundary decides which work deserves which model, which provider, which data path, how many retries to attempt, what approval loop to operate in, and which evaluation loop to use. Less glamorous than a chart, to be sure, but more relevant to production workflows. Most production architecture is less glamorous than the thing that sells the demo.
The teams that get this right won’t talk about having one “agent model”. They’ll talk about routes: Fast route. Deep route. Code route. Local route. Human-review route. And for each route, they’ll know when to use it, how much it costs, how often it fails, and whether the next release made it better.
This is where integrated agents become useful. The agent owns execution decisions instead of wrapping a model call in a little workflow theater.
The code that matters controls the router, the telemetry and the eval loop.
The model will keep changing. The decision boundary should belong to the team shipping the agent.
/Contact Us

Modernize your legacy with Focused
Get in touch