Blog
AI Agent Accuracy Is an Observability Problem
AI agent accuracy should be managed as observable production evidence: traces, evals, side-effect receipts, and release gates, not one average score.
Jun 5, 2026

Agent accuracy is a bad headline metric.
It sounds responsible. It gives the dashboard a number. It lets a team say the agent is 92% accurate, 84% accurate, or not ready until the number crosses a threshold invented during a planning meeting.
The rest of the journey then is production, and that is where the accuracy number turns into theater, and from there to the wall of shame.
The failures that matter are the wrong refund, the missed escalation, the silent tool call, the policy decision nobody can replay, and the answer that looked fine until a customer acted on it. Average answer quality does not sort these risks. AI agent observability is the work of sorting failures by consequence and evidence. Without it, accuracy becomes a vibes score wearing a decimal point.
I see this as the biggest pitfall in teams using accuracy as their primary metric, because the salient form of failure (hallucination) can mask a far greater number of problems that are far more insidious. The agent may state things that are true enough to read out in a final answer cleanly, yet be operationally incorrect in every possible way (e.g., it correctly summarizes the ticket, but incorrectly identifies the account in question; it correctly identifies the tool to call, but has the wrong scope in place; etc.). Further, an agent could correctly retry and return a successful response to the final answer, yet be silently incorrect for the side effects of that response (e.g., it correctly updates the invoice, but does so in a way that creates garbage in a dependent system that accepts it by default).
Accuracy has to answer a boring production question: what broke, who owns it, and what trace proves the next change made the system safer?
The score hides the consequence
A single accuracy percentage can mask a variety of errors.
One error is a style miss. The agent writes a clumsy sentence in a support reply and a human edits it. Annoying, cheap (maybe), recoverable.
Another error is one of state change: the AI’s answer caused something to happen as a result, and that something was incorrect. The phrasing of the answer was not a problem in these cases; the answer was factually correct. However, the system as a whole was not.
The operational consequence of different errors is not captured in a single accuracy percentage, because errors carry different consequence. Indeed, the harness has to record more than just the score of the model for accuracy to carry any significance. That is why monitoring the production AI agent has become production infrastructure. The monitoring harness has to contain the full trace of the production agent’s steps, including the plan it executed, the context it retrieved to perform each step, the full tool calls and results, the agent’s decision, the side effects received by the agent for each step, the agent’s fallback behavior for each step, and the final answer.
Honeycomb puts AI agent accuracy in the proper context. Telemetry data is already a lossy representation of system state, and another lossy layer on top of that is added by the AI. Observability teams deal with lossy signals already (traces, spans, etc.) so long as they are operational and allow the team to route around failures encountered during the investigation into the issue. AI agents are no different and the same mistakes (lossy representation) are made operationally by the agent.
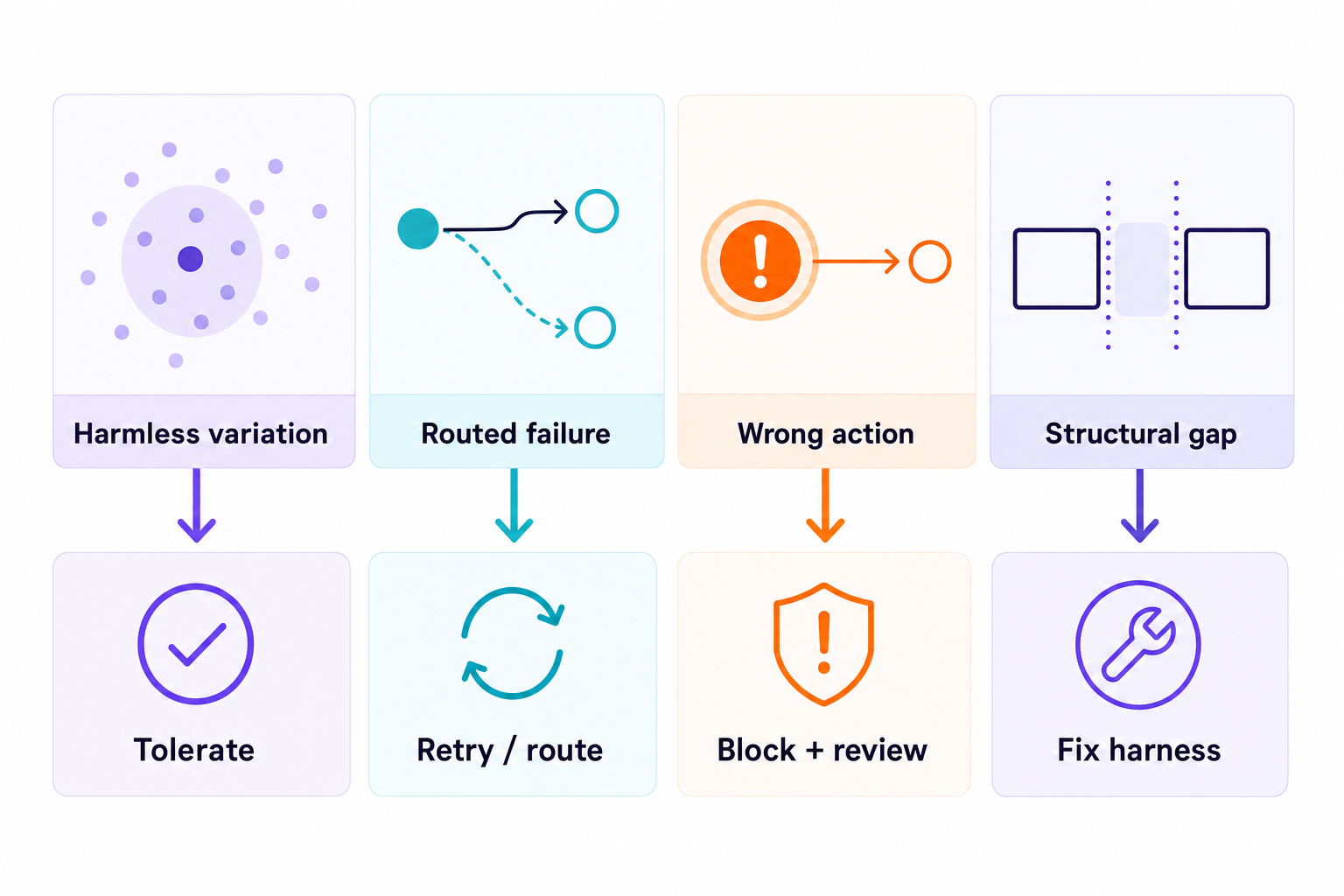
Early agents fail structurally first
Mature production agents fail in interesting ways. Immature production agents fail in less interesting ways before the team is confused as to why the agent failed in the first place.
The retrieval path points at the wrong corpus, the account context is incomplete, the agent has access to a tool but not the correct permissions to safely use it, the approval boundary is after the side effect rather than before it.
A June 2026 paper, Monitoring Agentic Systems Before They're Reliable, also comes to the same conclusion: early production AI agent systems are full of structural problems, which hide task-level errors. This paper talks about how to monitor a system in 3 scopes (within a run, across runs, and structurally) and then how to use variance to route the findings to either automated tracking or to human investigation. In this paper, 97% of the findings could be automatically tracked, and 2% or so would be left for the team to investigate on a case-by-case basis.
Accuracy at the end of the run is always late because the causes of the error will be within the structure of the workflow that generated the answer.
The first observability pass should ask three questions.
Within a run, did the agent complete each stage with the expected inputs, outputs, and receipts? Across runs, does the same case drift because the model is exploring or because the integration is unstable? Structurally, does the harness expose the state required to make the task possible?
This is the part that people gloss over because it does not seem to involve AI. But the harness is what exposes the state that the AI is using to begin with. Without the correct plumbing in place, the AI will never have the correct information to make accurate decisions.

Treat accuracy like an error budget
The budget of errors with different consequences should be defined by the production team, not by demanding perfect accuracy from the agent.
A draft-only content agent can be sloppy with wording because it’s reviewed in any case. A billing agent must be extremely accurate with account numbers because a wrong account number can cause bills to be sent to the wrong people with potentially disastrous results. A developer agent can propose to add a risky diff of code if the CI process, subsequent review, and rollback capability are all in place to handle the worst case. An access-management agent must treat identity ambiguity as a hard stop because incorrectly granted access to data about another person could be a serious breach of privacy.
A harness should say “for this task, these types of errors are tolerable, for this task these types of errors can be retried, for this task these types of errors can be routed to someone else, for this task these types of errors are a hard stop and must be blocked, for this task these types of errors must be escalated, for this task these types of errors become a new eval for the model”. All of these decisions should be embedded in the harness, next to the tools and state transitions of the system, and not in a polite prompt that is asking the model to be careful about something. The side effect of the prompt is not something that can be handled by prompt text, runtime code can.
The same evaluation that uncovered a failure in the agent should be able to be used to modify the harness. Evaluation should steer changes to the harness.
The dull implementation detail here is that every action the agent takes (risky or otherwise) should have a side-effect receipt. So rather than just logging a change of state to a database, the system would generate a receipt for the action that includes: input, the selected account, the tool contract/schema used, the scope of the authorization used, the model’s output, the human approval state, the resulting external identifier(s), etc.
That is how accuracy turns into operations.
The feedback loop has to close
The manual improvement loop as described recently in the LangSmith Engine note from LangChain follows this pattern: trace to failure, then prompt or code to fix, then eval and test, then ship and repeat.
It is good to see monday’s LangSmith case study, where evaluation feedback loops for Service reports became 8.7x faster, down from 162 seconds to 18 seconds, with offline evaluation safety nets, and online production monitoring against traces. This is a concrete example of how evaluation can become code-backed production practice (as opposed to occasional spreadsheets).
So long as an agent is being run as a transcript of prompt and answer, there is little in the way of release evidence of what was run to test it out. Evaluation pipelines for LangGraph agents turn the run of an agent into a versioned object, comparable, gatable, and improvable by the team.
For production-grade AI agents, accuracy is a property of the loop, i.e. offline evals catch known regressions, online monitors catch real drift, trace analysis names new failure classes, harness changes move the boundary, release gates keep the fix from breaking another path.
What to instrument first
Start with the places where accuracy can become damage.
Every tool call (even scripts) should have a full record of: the selected entity (accounts, etc), the scoped credentials (auth tokens, etc) used to call the tool, all of the arguments passed to the tool, the full response from the tool, and the full external side-effect receipt (e.g. what records were updated, etc). Every retrieval should have a record of all the source IDs and versions it considered, plus the reason it chose the retrieval context it used. For every human approval boundary (e.g. approval for a particular action), it should be possible to determine who approved, what changed as a result of that approval, and whether the agent continued from the exact same state after approval (as opposed to after another action).
Add evaluator verdicts where they can change behavior. Groundedness score for instance is useless if nobody reads it. But a verdict that for instance blocks a deploy, routes a case to review, opens a ticket, or even updates a regression set of failed evals to run, is useful as it produces operational evidence of accuracy.
The seductive version of observability is a trace store full of nice looking spans while the agent continues to make the same mistake. And nothing changes. Observability has to produce action. Open the ticket. Add the eval. Patch the tool contract. Move the approval gate. Kill the unsafe route.
Own the next change.
Accuracy belongs to the system
Once an agent is integrated with tools, memory, policy, approvals and external systems then accuracy becomes an attribute of the entire runtime.
A clean percentage is misleading because it pretends that the model vendor is responsible for the accuracy of the AI agent. They are not.
Accuracy of an Agent increases as long as the system is able to distinguish between errors of concern and errors that do not matter at all. Traces have to prove consequence of actions performed by the agent. Evals have to have the ability to preserve regressions that might occur during retraining. The harness has to route risky behavior to the correct human(s). The release process has to be able to prove that a fix for an error actually fixed that error.
And the important note here: average accuracy is just a starting point for an AI powered agent. But in production, accuracy means creating an observable loop of error, cause, fix, and updated runtime, that again and again catches the right mistakes, explains them to us, and then fixes them before someone else has to pay for that same mistake.
/Contact Us

Modernize your legacy with Focused
Get in touch