Blog
AI Agent Orchestration Needs Receipts
Agent orchestration needs a side-effect ledger that records operation keys, receipts, retries, compensation, and ownership before mutating tools touch production systems.
May 16, 2026

Orchestrating AI agents breaks in the boring place of all: between issuing a tool call and the tool call having its intended side effect.
As tool calls transition from being client tools executed by application code to server tools executed by models, there is a point in the system where the language and the abstraction used to describe the tool use breaks down. A tool call becomes a runtime transaction. The work done by a tool affects databases, makes payments, sends emails, creates tickets, etc. A retry storm, or even a simple retry, now has significant production consequences.
Agent tools need receipts.
Tool Calls Are Side Effects With Better Marketing
Anthropic's tool-use docs split server tools from client tools. A client tool is executed by application code, and then the application sends tool_result back to the model. This is where language ends and production begins. Databases get mutated. Payments get made. Emails get sent. Tickets get updated. Credentials get used.
I see this boundary get described as a function call. Better: side-effect boundary. These systems do not have a durable receipt right now.
What proves the side effect in an agent runtime? The request IDs from external vendors, the changed rows in the business system, and the receipt the runtime saved before the model moved on. It takes human eyes reading through three different systems (and writing glue code along the way) to answer questions like "Did this exact tool intent already cause this exact side effect?" if the runtime cannot track the side effects caused by tool calls inside the model loop.
The Old Backend Pattern Still Applies
Normal API work has already figured this out. For example, Stripe supports idempotent requests for POST, so a caller can retry after a network failure without charging the customer twice. It tracks the original parameters for a given idempotency key, so if the key is reused with different parameters, it will not be treated as the same operation.
AWS Lambda Powertools describes idempotency records with INPROGRESS and COMPLETE states, payload hashes, stored responses and an expiration for the record. This is a tiny state machine around a side effect. That's all that's required for an agent runtime to safely handle model-intent-to-change-the-world calls.
The transactional outbox pattern: write the business state and the outbound message in one database transaction, then deliver from the outbox. AWS writes about the duplicate-message problem for this style of delivery and recommends idempotent consumers that track processed message IDs.
The deterministic backend, for example a Java or Python service, calls a service endpoint with fixed intent semantics. Booking a hotel room is boring in exactly the right way. An agent tool call is produced by a model loop that can re-plan, retry, branch, summarize state, and call the same tool again. The runtime has to record the intent before the side effect is produced.
What the Ledger Has to Know
Tool Ledger. Side-Effect Journal. Orchestration Transaction Table. The name is unimportant. It is a table with a specific shape.
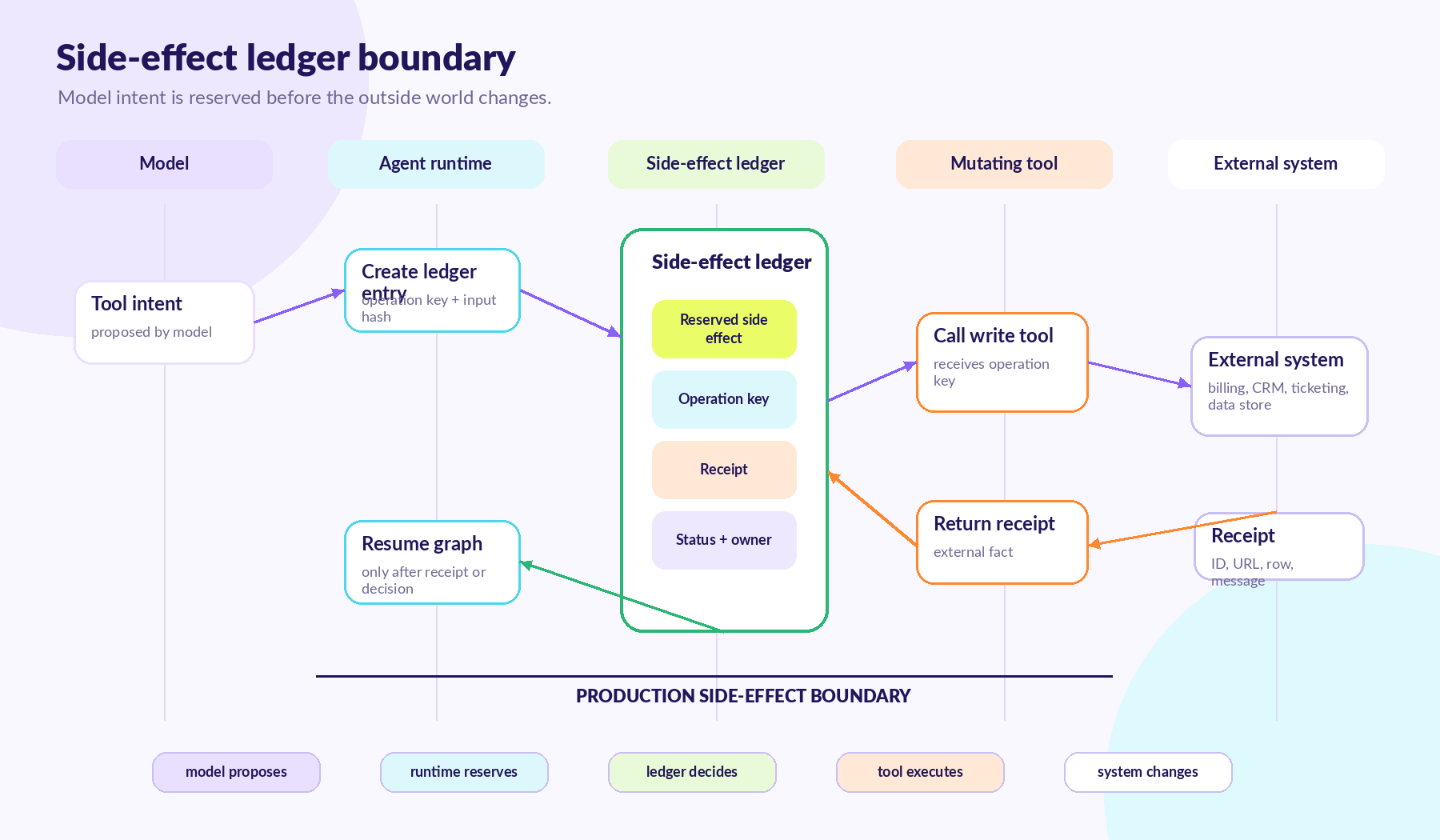
A side-effecting tool call needs a record before execution:
create table agent_tool_ledger (
id uuid primary key,
run_id text not null,
step_id text not null,
tool_name text not null,
input_hash text not null,
operation_key text not null,
status text not null check (status in (
'planned',
'in_progress',
'succeeded',
'failed',
'compensating',
'compensated'
)),
receipt jsonb,
compensation jsonb,
error jsonb,
run_trace_id text,
owner_service text not null,
created_at timestamptz not null default now(),
updated_at timestamptz not null default now(),
unique (tool_name, operation_key)
);
That unique constraint is the point.
The record would hold: tool name, normalized input hash, run ID, graph step, owner service, run trace ID, status, receipt, and compensation metadata. On conflict, the application checks the stored input_hash against the new input_hash. Same key with different input is a bug. The receipt is the external fact: Stripe charge ID, Zendesk ticket ID, GitHub comment URL, invoice number, database primary key, email provider message ID.
No receipt, no production claim.
Retry Safety Has to Be Designed Before the Retry
A retry policy is essentially a duplicate side-effect generator wearing a reliability costume.
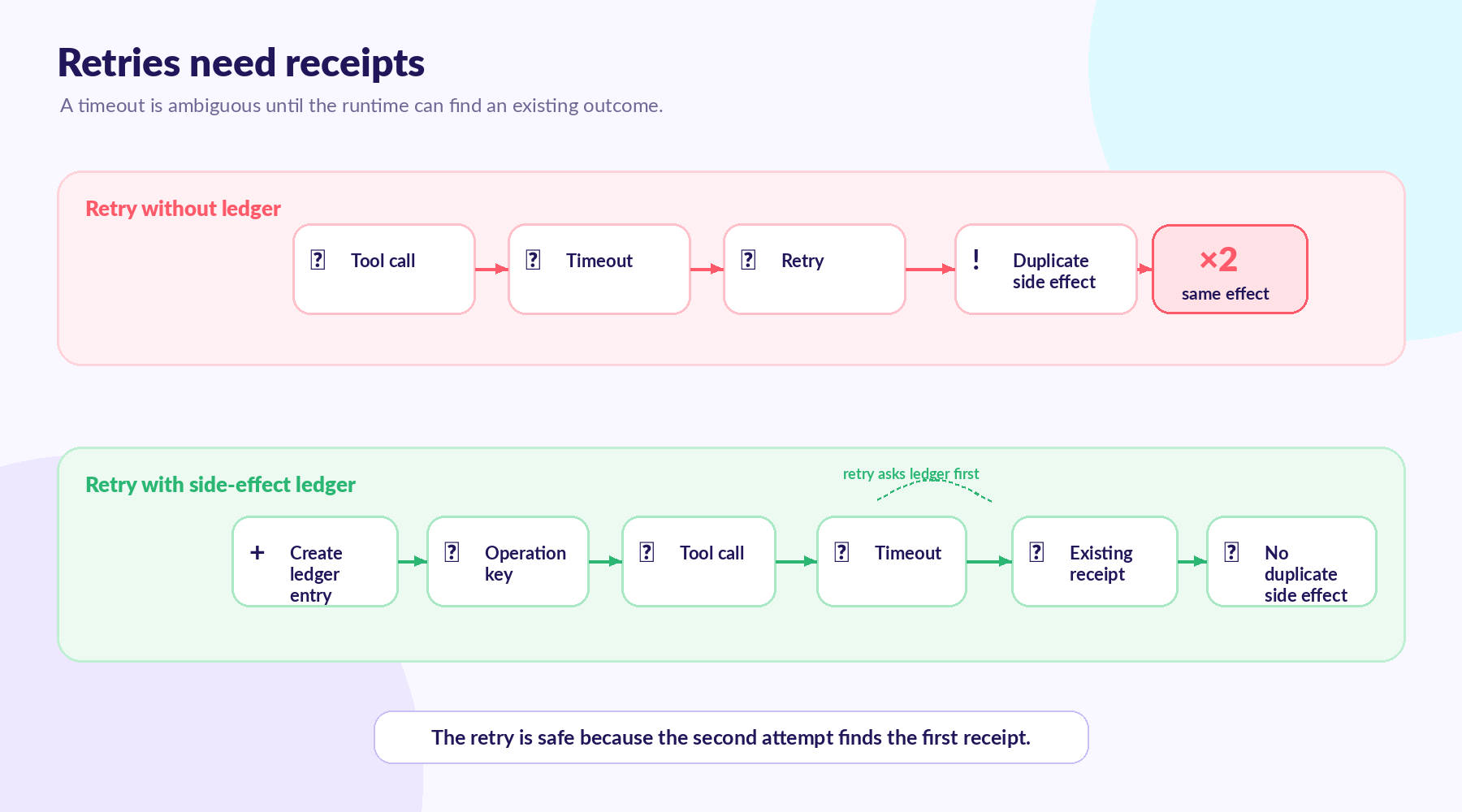
Temporal's Activity documentation recommends idempotent Activities because they can be retried. A non-idempotent Activity can corrupt application state even when the distributed system is functioning correctly. The runtime's retry policy does not make the agent reliable by itself.
This is where agent systems get uncomfortable. Because we've instrumented our system to retry on transport failure, we can easily believe that we're retrying on transport failure, when in reality we're just retrying on a model of the world that observes a timeout and decides to go down a different path. So, for example, after refunding a customer the model may decide to create a support note, and then the model may decide to refund the customer again in a summary step, losing the receipt from the first attempt. The model may ask a human for confirmation in the meantime and then resume with stale tool context. The model may even run a background subagent that decides to go down a different path in order to arrive at the same conclusion.
This intent cannot be raw JSON. Models produce irrelevant differences. Field order changes. Natural-language notes shift. A good operation key comes from the business operation. The model's token stream is too noisy. refund:{tenant_id}:{payment_id}:{reason_code} beats a hash of the entire prompt. comment:{repo}:{pull_request}:{review_run_id} beats a blob of generated markdown.
That ownership boundary corresponds to the ownership of the credentials for the tool. In agent systems, the authentication of the agent to the external system should start with the workload identity. In AI Agent Authentication Starts With Workload Identity, we discussed the reasons why the secrets should not be passed around like party favors. This same principle applies here. The runtime should not make up the side-effect semantics for a tool that is not owned by the runtime.
Observability Without the Receipt Is Theater
But traces do not, by default, create a business-level uniqueness boundary.
Joining traces to ledger entries changes what agent observability can do. The trace explains the path after the incident. The ledger table can drive behavior during the incident: suppress the duplicate, resume from a receipt, trigger compensation, alert the owning team, or block the next step until a human approves the ambiguous side effect.
That is the difference between a dashboard and a control surface. The trace is evidence. The ledger is state.
Evaluations also get a lot better. In place of "the model called the refund tool", the useful check is one planned refund, one succeeded ledger entry, one receipt, zero duplicate external effects after a simulated timeout. In Everybody Tests, we recognized that people are already testing with the feedback loops they have today. The transcript is too thin to capture all the detail.
The Tool Interface Should Expose the Contract
The contract for a side-effecting tool should be defined near the definition of the tool itself. That contract should describe the operational facts that the runtime can enforce for that tool. A side-effecting tool contract should answer:
- Is the tool read-only or mutating?
- Who owns the tool?
- Which fields form the operation key?
- Which external receipt proves success?
- What status means the side effect is safe to retry?
- What compensation path exists when the effect is wrong?
- How long does the ledger entry live?
This is where MCP and other tool packaging efforts need to "grow up" to support packaging of tools for agents to use in production. Such interfaces are not just "packaging" and must be agent-operable - typed, permissioned, inspectable, retryable, and owned by a service. This is the real product, and it is a far cry from a mere interface for the agent to discover and call a tool.
A tool registry that simply says a tool exists is table stakes. A registry that says a write tool mutates customer billing, requires workload identity, lists the operation-key fields, emits a specific external receipt, and pages the service owner on ambiguous completion starts to look like production infrastructure.
Boring. Also useful.
The Runtime Should Refuse Unsafe Writes
Ledger policies for mutating tools run the show.
Read-only search tools remain lightweight, (retrieval, ranking, summarization, classification). Write tools charge cards or email customers. Write tools have their own set of problems but follow a different set of rules. For write tools the runtime should require a ledger policy before registration. The tool owner supplies the operation-key builder, receipt parser, retry rules, and compensation metadata. The runtime supplies the reservation, status transitions, trace joining, and audit events. The rest of the orchestration layer checks the side-effect ledger before running the tool and after it fails. The eval harness tests the duplicate paths for the tool. The on-call team can see stuck in_progress rows before the customers do.
LangGraph Agent Error Handling in Production. Here, handling errors in tools called by an agent is more than simply handling exceptions that occur when the tool is called. The side effects that occur before the error is surfaced, especially around a timeout, are the real problem the error handling has to address. The ledger is where the system goes looking for evidence.
That last point matters. Agents can keep going after an error has occurred. But in production, continuing can be reckless.
Own the Receipt
The gold rush version of AI agent orchestration wants better planners, bigger context windows, and more tools. Fine. Those help.
The production version needs a boring table that answers whether a tool call already did the thing.
That table won't demo well. Nobody cheers for a simple unique index on (tool_name, operation_key). But that's exactly what this table is. And it will save a team from having to refund, email, provision, delete and apologize (for the mysterious model) twice.
The model can be probabilistic. The side-effect boundary cannot.
Own the receipt.
/Contact Us

Modernize your legacy with Focused
Get in touch