Blog
Agent Orchestration Belongs in Code
Agent orchestration works better when loops, retries, fanout, and approvals move from prompts into executable code with a narrow harness boundary.
Jul 4, 2026

Agent orchestration is moving from prompt choreography into code.
There’s a really cool feature of LangChain’s new dynamic subagents under that subagent headline. A root model can now write a tiny program, run it in an interpreter and have that program work out step by step within a narrow task() bridge. For example, a prompt can ask a model to cover every file, then the model can write a loop that enumerates those files instead of pretending the request itself creates coverage.
The piece we kept missing from the ‘ai agent orchestration’ conversation is: tell the model to plan, delegate, verify, retry, & synthesize. Then ask it to remember the entire flow as tool results get streamed back into the context window. Hope is not a strategy, and is expensive.
Documentation for dynamic subagents in LangChain dynamic subagents documentation explains the “cleaner contract”. In this model, the interpreter code dispatches subagents that were configured for the task at hand, in series, in branches, or in parallel in batches. The model is still deciding what work to do and the code is for coverage.
The long-standing harness problem in real AI agents real AI agents is showing up again here. The framework conversation has value ONLY when it graduates to deployment / tracing / evals / ownership. That runtime shift previewed at LangChain’s Interrupt runtime shift LangChain previewed at Interrupt conference is already manifesting in the orchestration layer.
The old pattern samples work
For small action chains the normal agent loop is perfectly fine. The model computes a course of action, invokes a tool, reads the tool’s output, invokes the next tool in the chain, and so on. For very small tasks this way of thinking is perfectly adequate.
Batch work breaks the rhythm.
A security review of a route directory in a filesystem is not a vibes exercise. The agent discovers the files, dispatches the review for each of the files found, keeps track of line numbers for code reviews, removes duplicates from the findings, verifies the severity of the findings etc. until a full report is generated. Turn-by-turn delegation as described above requires the model to keep a lot of bookkeeping in memory. The model can dispatch subagents, but the number of times this is needed, the retry shape, etc. is all in text.
LangChain has a good launch post for dynamic subagents launch post by LangChain for dynamic subagents. They mention the example of one subagent per page of a 300-page document. The important line in that example is “Promise.all”. And once the subagent orchestration is written as code, coverage is no longer a prompt request.

Inside the interpreter, the shape is boring in the best way:
const issuesSchema = {
type: "object",
properties: {
issues: {
type: "array",
items: {
type: "object",
properties: {
file: { type: "string" },
line: { type: "number" },
severity: { type: "string", enum: ["high", "medium", "low"] },
description: { type: "string" },
},
required: ["file", "severity", "description"],
},
},
},
required: ["issues"],
};
const files = (await tools.glob({ pattern: "src/routes/**/*.ts" }))
.split("\n")
.filter(Boolean);
const reviews = await Promise.all(
files.map((file) =>
task({
description: `Review ${file} for auth issues. Cite line numbers and severity.`,
subagentType: "reviewer",
responseSchema: issuesSchema,
}),
),
);
const highRisk = reviews
.flatMap((review) => review.issues)
.filter((issue) => issue.severity === "high");
highRisk;The code follows the current Deep Agents interpreter docs: programmatic tool calling, where applicable and after allowlisting, is exposed under the tools.* namespace, and dynamic subagents are exposed through task() when configured.
One can also note that the architecture described is very similar to the earlier one: the context window is no longer just a temporary storage for intermediate values. The interpreter holds a working set of values of interest, and the model is presented with the relevant result.
RLMs make the direction obvious
Recursive Language Models (RLMs) follow the so-called RLMs pattern. Here, long input strings are considered as external environments which are loaded into a REPL (Read-Eval-Print-Loop) of a language model. In this REPL, the model generates code that examines parts of the input string, decomposes the task into a set of sub-tasks, recursively calls language models on short code snippets. The authors report inputs that are two orders of magnitude larger than the context window of the corresponding RLM, and significantly better than direct model calls as well as other approaches for dealing with long input strings. report inputs up to two orders of magnitude beyond model context windows
LangChain's RLMs in Deep Agents post translates that to agent infrastructure. Deep Agents keeps the working set in interpreter variables, selects context slices, dispatches subagents with task(), and synthesizes the objects those subagents return. The post also reports an OOLONG proof of concept where the REPL-backed agent performed better at 128k context than the plain agent on long-context aggregation work.
This is the correct mental model for ‘agentic ai architecture’. It shouldn’t be sitting in front of a huge pile of context trying to work out what to do next. Instead it should have a work queue, a loop and typed return types. The model should apply itself to the judgment of how to decompose a problem into constituent components, and then synthesize those components back together into solutions, as opposed to trying to keep track of each individual item in a sequence, and then recall them in order.
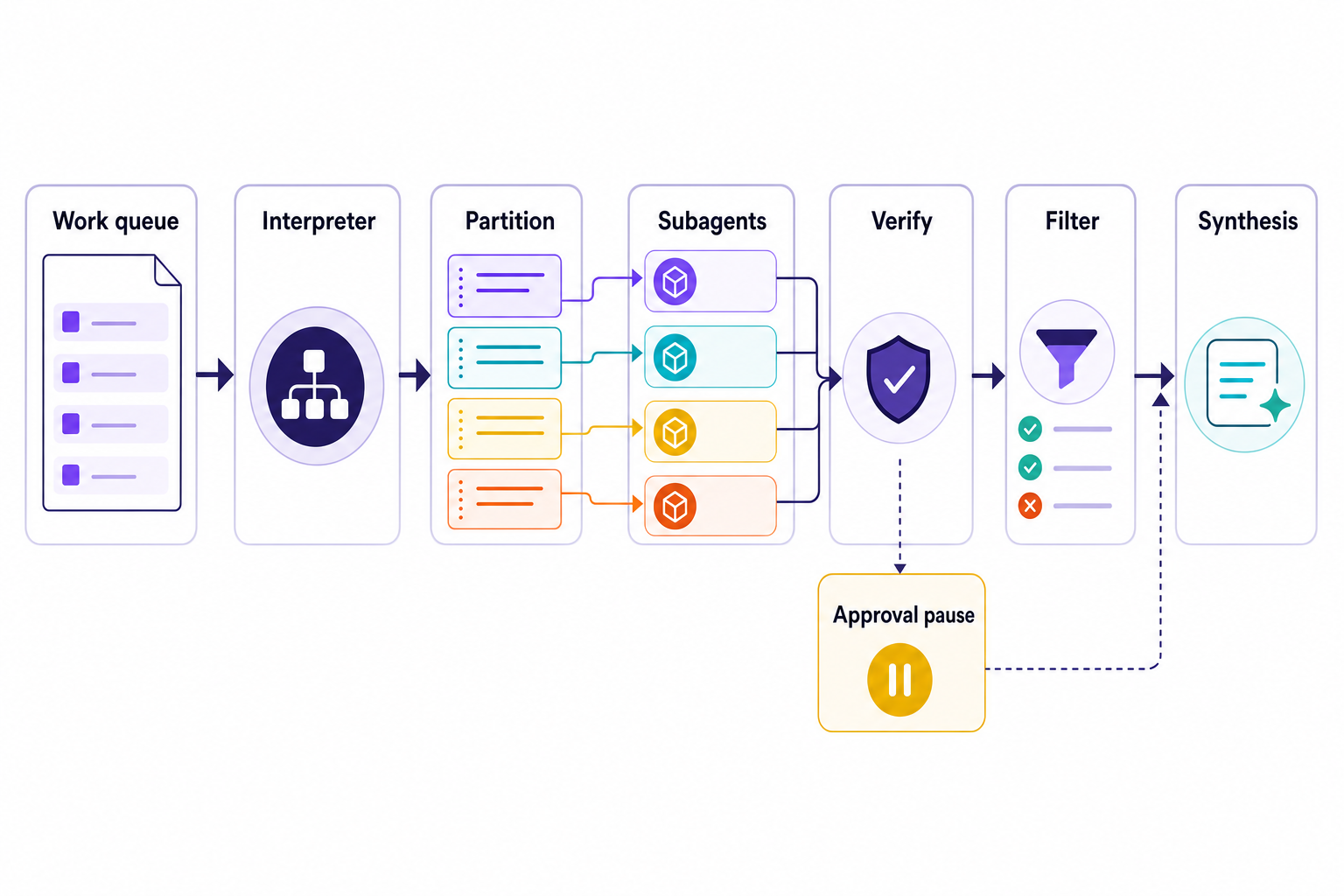
Claude Code is heading down a similar path. Anthropic says dynamic workflows let Claude write orchestration scripts that run parallel subagents, save progress, check work, and return one coordinated answer. Similar direction, different harness. Agent orchestration is becoming executable.
The security question moves to the bridge
Another set of fears come into play for teams who fear the agent writing code. They then imagine the full complexity of a sandboxed shell: package manager, file system, network, etc.. All that new found chaos a bored engineer can unleash on a Friday. That is one set of fears.
Interpreters are smaller.
QuickJS interpreter code has no host filesystem, network, shell, package manager, or even clock by default. It can compute, hold variables, and print to console. The two explicit bridges are programmatic tool calling through an allowlist and subagent dispatch via task().
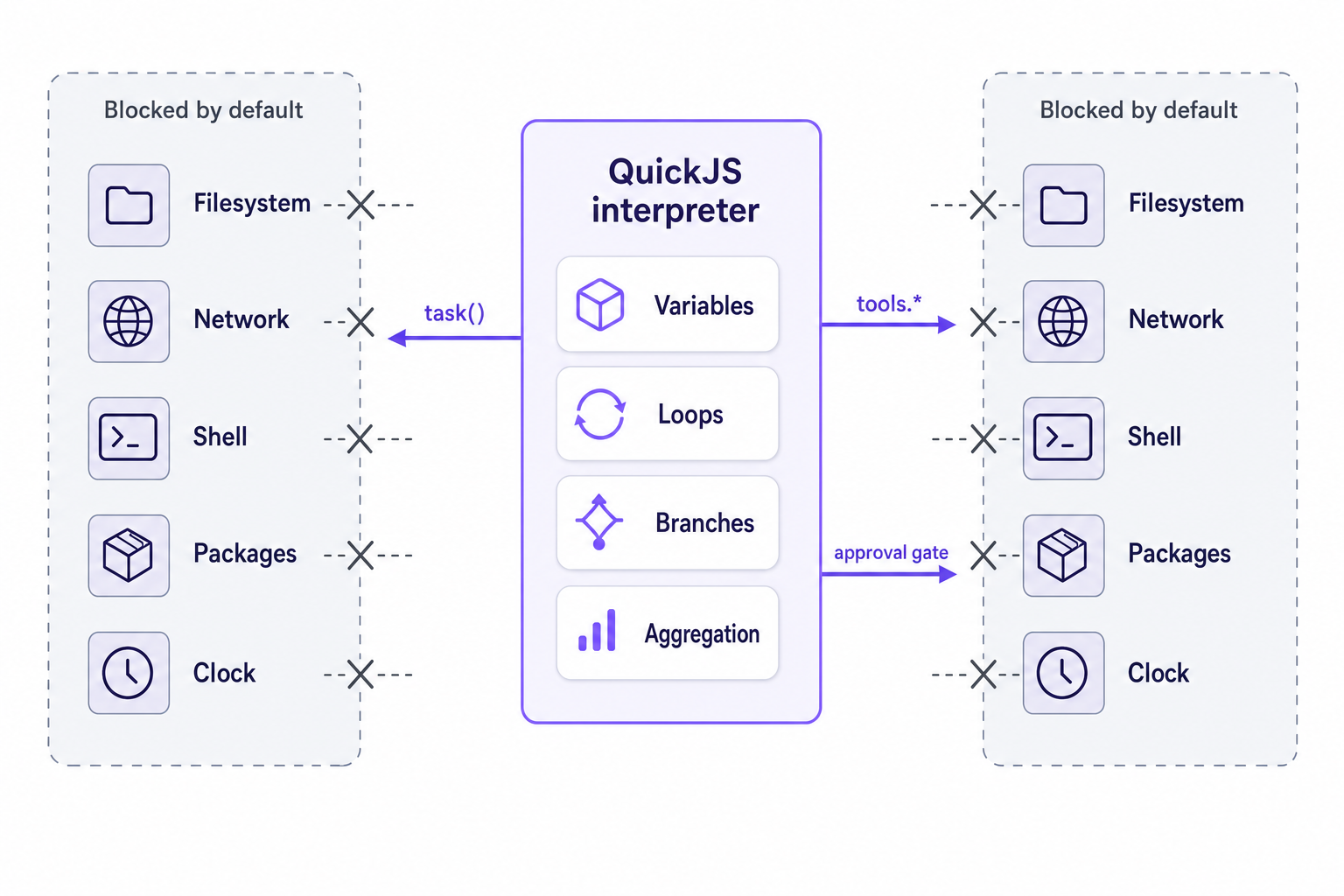
LangChain’s post on running untrusted agent code without a sandbox running untrusted agent code without a sandbox describes the boundary. QuickJS runs in WebAssembly. The host code exposes only the capabilities that we intend for the untrusted code to use. The WebAssembly project’s front page describes Wasm as a “memory-safe, sandboxed execution environment for general-purpose programming” WebAssembly project describes Wasm as a memory-safe, sandboxed execution environment. The QuickJS-ng home page describes QuickJS as a “small embeddable JavaScript engine” QuickJS-ng describes QuickJS as a small embeddable JavaScript engine. Small here means less surface area, which is what I care about. If the core JavaScript engine has less surface area, then there are fewer strange ways in which odd privileges could have been introduced to the orchestration code.
Note that full sandboxes are still relevant today. LangChain’s sandbox guidance for example lists the following features for a sandbox relevant for coding, data analysis, browser etc. work (where an agent usually works with many dependencies and thus often needs to run for a long time with previous runtime values of the sandbox being used in a controlled way): isolated filesystem, restricted for making outgoing net connections, limited resources, controlled reuse of prior runtime values of the sandbox, full kernel level isolation. In short, an agent simply replaces a computer for such work.
An interpreter is not a general-purpose sandbox but rather a tool to fulfill a specific set of tasks such as loops, conditional statements, filtering, aggregation, and fanout within a given capability. For tasks where an agent needs to actually run on a machine, a full sandbox is more appropriate. For tasks where an agent needs to run orchestration, an interpreter is more suitable.
Meta's Agents Rule of Two details the risk: until prompt injection is solved, an agent should not exceed two of untrusted inputs, sensitive or private data, and external state change or communication in a session. Interpreter bridges give the harness a place to enforce that rule: define which tools exist, which subagents run, where approval happens, and what data crosses back.
This is where the harness owns the orchestration boundary. The model proposes a program. The harness decides what the program can touch.
Executable orchestration has receipts
Programmatic orchestration will create a whole new set of script bugs. Simple scripts can still pass the wrong schema. More complex scripts can spawn too many subagents, or filter away the signal in the jobs submitted. A stale interpreter variable can survive across turns because state persistence was configured that way.
Good. Those are inspectable failures.
For LangChain’s interpreter persistence there are three modes: “thread”, “turn” and “call”. So middleware stores the state of the interpreter between the turns in “thread” mode. Every “eval” in “call” mode starts from scratch. As with tool allowlists, task() visibility, concurrency limits, schema contracts, and approval gates, the trade-offs here need to be discussed in code review, not locked away in prompt folklore.
This is a warning from the dynamic subagents docs and it should go into the checklist: task() dispatches from within an already-running eval call. Parent-agent interrupt_on approval workflows are not enforced per task dispatch. That means gate the eval tool when approval has to happen before the orchestration runs.
That line belongs in the operating model.
First, there is a huge benefit to creating a record of the script that was run, the subagents that were spawned, the calls to tool-bridge, the results that were filtered, the approvals that were issued, and the final synthesized result. Without this record, a fanout-based system is left to its own devices, a beautiful machine with no receipts for what was done. Agent UI is runtime infrastructure, Agent UI is runtime infrastructure for the simple reason that products need typed handles to the various tools, to issue approvals, to manage subagents, to handle errors, and to track the state of a workflow. When we go to programmatic orchestration, the issue becomes even more pronounced. The events that are generated by subagents are the only way to get insight into what actually happened during the run of the main program.
Observability too follows this trajectory. As orchestration moves to code, traces must reveal the program boundary as well as the modeled spans between them. Observable agentic systems observable agentic systems are seen by their teams as a ‘movie’ of how the system behaves, where each frame of the ‘movie’ of execution is visible to them as a sequence of operational events. They can see the exact point at which an interpreter’s call started a worker, what that worker returned, the exact point at which a bridge call crosses a capability boundary, and where synthesis is dropping information. This is how their operational dashboard transitions from ‘theater’ to ‘operational evidence’.
Own the loop
The classic approach to orchestrating many agents was always about choosing the right supervisor pattern: supervisor, swarm, handoff, or router. So much beautiful vocabulary that almost never gets used in practice.
The more important operating question is where the loop lives.
By writing a simple loop, we can in effect give the team (a) coverage, (b) a schema to work with, (c) specific replay points of interest, (d) approval gates for specific pieces of output, and (e) traces of exactly what the model was doing. However, the model still has a real purpose: deciding (1) how to decompose the problem, (2) which specialists to bring to bear, (3) which facts are salient, and (4) how to pull it all together into a coherent answer. The harnessing code then implements these decisions in the form of a program of finite scope.
That’s where the real value is in dynamic subagents, RLMs, and Claude Code workflows, it’s all about executable orchestration within a runtime that knows what code to run. (Bigger prompts & more sophisticated supervisor labels don’t cut it here).
Own that boundary. Trace it. Review it. Gate it.
Let the model write the loop. Don’t let the loop float around in the prompt.
/Contact Us

Modernize your legacy with Focused
Get in touch