Blog
The Agent Harness Is the New Lock-In Layer
The agent harness is becoming the real lock-in layer for enterprise AI because routing, traces, evals, memory, policy, and credentials live above the model.
Jun 4, 2026

The agent harness is where model lock-in gets expensive.
In cloud computing the compute itself is rarely the issue that locks a company into a provider, rather it is the tools and layers around that compute. ARM templates, CloudFormation, Terraform and others created a new infrastructure boundary that a team could control. Now a similar shift is occurring with agents in AI. The model calls are easy enough to switch out, painful yes, but evaluation work already absorbs that pain. The lock-in surface is shifting into the agent harness.
Neil Dahlke wrote a useful post on model neutrality and AI vendor lock-in: model neutrality and AI vendor lock-in. As Dahlke wrote in that post, compute is rarely the lock-in point. The tooling above the compute is. ARM templates, CloudFormation, and Terraform tried to provide a neutral provider-agnostic control layer above the compute providers. The useful layer let a team mix and match, negotiate, and keep options open.
Teams realize that while raw compute (i.e. servers) is cost competitively available in the cloud, it is the tooling about the compute that matters. Teams spend time with ARM templates, Terraform, CloudFormation, CI, policy, and review. That effectively becomes a new lock-in surface. With agents, that lock-in surface has moved up one level of abstraction again.
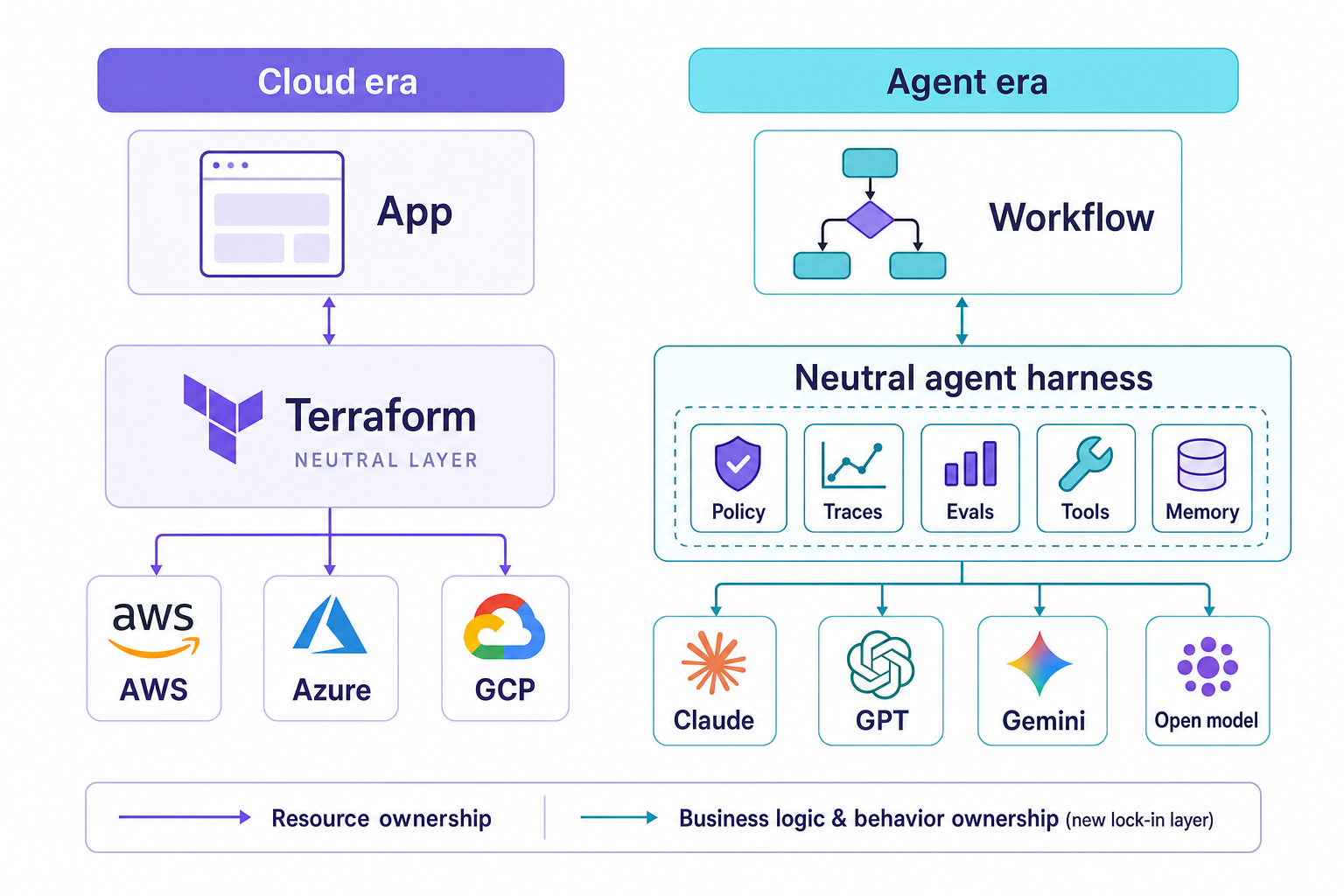
The expensive dependency lives above the model
As noted above, model calls (whether powered by closed models like Claude and GPT or open models) are becoming increasingly easy to switch out, but that is to say they are still painful to switch out (and as with anything else that has evaluation work involved, the pain typically migrates down the call stack in subtle ways that are not immediately apparent. For example, prompts begin to drift in more 'subtle' but still real ways, the behavior of tool calls involved in the workflow also begins to drift, latency and cost profiles begin to shift in non-obvious but again real ways).
The real dependency is in the tooling surrounding the model call.
The lock-in surface has moved up the stack from raw compute to a tooling level within the agent harness, and provider SDKs are reaching up. OpenAI's agents SDK guide OpenAI's agents SDK guide covers orchestration, tool evaluation, state, approval, and related controls for multi-step work performed by specialist agents inside the harness. OpenAI's tracing documentation OpenAI's tracing docs describes traces for generations, tool calls, hand-offs, guardrails, and workflow spans. The Claude Agent SDK for Python repository Claude Agent SDK Python repo contains APIs for session-based work, hooks, permissioned tool use, resumable conversations, and a bundled Claude Code CLI. Vertex AI's Agent Builder Vertex AI Agent Builder enables users to build, govern and run production agents within Gemini's Enterprise Agent Platform.
That is the move. Providers are not stopping at the endpoint. They are moving into the harness.
Once a neutral layer of logic is locked into a provider-specific harness, such model switching becomes a matter of migrating the business logic in the harness. Traces, evals, and retries can then be easily moved to other models. Memory, credentials, and release gates are already managed by the harness.
Agent neutrality happens during the run
Cloud neutrality was a boardroom phrase until something broke. A renewal came up. A region failed. A bill got weird. A team had to decide whether it could move a workload.
Model neutrality has a shorter clock. It shows up inside a single agent run.
Supporting a customer service representative, such an agent could use one model to classify customer intent and another to write policy-grounded answers. That answer could then be used to generate structured JSON for a customer relationship management (CRM) system, with a smaller model used to summarize the entire conversation for memory. A software agent might use a planning model to plan out a series of actions, a code edit model to make changes to software, a long-context repository search model to search through large amounts of code to find specific information, and then an open model for background triage, etc. The governed workflow is the unit that matters.
That is why agent harness is the useful phrase here. Generic lock-in misses where the surface of lock-in has moved from creating templates for infrastructure to actually harnessing agents and models.
We have already covered why agentic AI architecture needs model routing. The argument now moves up a level, to whether routing is still acceptable when it is offered by the provider as a feature. Provider-supported routing can help. Provider-owned routing can become another part of the tool the customer is locked into.
The harness is the control plane for behavior
Sydney Runkle of LangChain wrote recently on building a custom agent harness. Her view is model + harness. The model supplies language and reasoning. The harness supplies the context for the model to run within, including tools, policies, environments, memory, delegation, approval, retries, and the rest of what makes the model function as a system.
That definition is more than a neat formula. It explains why enterprise agent work keeps drifting toward infrastructure.
The harness is where a team defines what context the model will have. The harness is where a team defines what tools the agent will use. The harness is where business policies sit. The harness is where environments get tested. The harness is where memory, delegation, approval, retry logic, guardrails, cost logic, data boundaries, task boundaries, and workflow boundaries live.
This is why at Focused we have long taken the opinionated position that LangGraph is the right infrastructure for the enterprise for building out AI Agent architectures LangGraph as the enterprise agent foundation. The fans of particular frameworks can get worked up about their pet frameworks, but what matters about infrastructure is who owns the graph, the state, the interrupts, the model routes, and the traces. Production contracts, for release, usage, and operation, are what matter. That is why we keep pulling enterprise agent architecture toward LangGraph.
Runtime routing is already a code path
The model-neutrality argument can sound abstract until it shows up as a few lines of middleware. LangChain's current docs for selecting a model at runtime in Deep agents use runtime context, wrap_model_call, ModelRequest, init_chat_model, and request.override(model=model). The core LangChain docs show the same pattern for dynamic model selection middleware.
from dataclasses import dataclass
from typing import Callable
from langchain.agents import create_agent
from langchain.agents.middleware import ModelRequest, ModelResponse, wrap_model_call
from langchain.chat_models import init_chat_model
@dataclass
class Context:
route: str
environment: str
models = {
"planner": init_chat_model("anthropic:claude-sonnet-4-6"),
"structured_output": init_chat_model("openai:gpt-5.4"),
"long_context": init_chat_model("google_genai:gemini-3.5-pro"),
"background": init_chat_model("openai:gpt-5.4-mini"),
}
@wrap_model_call
def neutral_model_route(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
model = models.get(request.runtime.context.route, models["background"])
return handler(request.override(model=model))
agent = create_agent(
model=models["background"],
tools=[],
middleware=[neutral_model_route],
context_schema=Context,
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "Draft a refund-policy summary."}]},
context=Context(route="structured_output", environment="production"),
)
Observability belongs above the provider
Provider-native traces are pretty great. I wouldn't even say they are bad to allow inside an org. If all an SDK does for generation after generation is record spans for tool calls and handoffs, including guardrails, that is useful.
But the enterprise observability problem is cross-provider by nature. The production question is not only, "what happened inside the OpenAI run?" It is, "which workflow ran, which route was selected, which credentials were exposed, which tools mutated state, which evaluator fired, and did the same failure family appear when the planner used a different model?"
That question belongs to the harness owner.
Governing a software agent rhymes with evaluating a language model, except the evaluated unit is the harness around the model. AI agent evaluation steering the harness and agent benchmark scores measure the harness both point at the same control surface: routing, prompts, tool selection, policy, and release gates.
A neutral harness keeps traces and evals attached to the business workflow. A provider harness keeps them attached to the provider path. That difference may seem small until an incident review needs to span across three models, two tool systems, and one customer-facing workflow. It is hard to replay that in a vendor console.
The enterprise mistake is buying the harness by accident
Enterprise teams rarely set out to give a model provider control over the agent operating model. It happens through convenience.
A provider will have an excellent quickstart that gets a team up and running in minutes. Another provider might have a great hosted trace viewer. And when a team is first implementing AI agents at a company, there will be people who want to use the agent to approve an action (e.g. sending an email, creating a new record, etc.). Naturally, that provider's SDK will have the hooks to implement that approval logic. Memory will be stored there. Evaluators will be added there. The agent will be deployed there. Credentials will be managed there. And after 6 weeks or so, even though the agent can technically be used with other models, the entire system will have been set up within the confines of that single provider's SDK.
This is how lock-in works when the surface area is productive for long enough.
The evidence needed for review should stem from the harness and relate directly to the workflow. If a routing change needs a pull request, that pull request should contain the updated route table, the diff between previous and new eval sets, a sample trace showing tool permissions stayed bounded, and a rollback section. Provider-console inspection covers one path. Harness-owned evidence covers the workflow operations and compliance will inspect after the first production incident.
Reject provider SDKs? No, because they are productive. But don't let them inadvertently build out an operating model that becomes hard to undo later. Decide who is going to create durable contracts in the end, as if they were not durable already, and make sure that layer sits outside any one provider SDK.
Focus on owning the workflows and pass the enterprise contracts into the provider SDKs. A workflow should be able to run against Claude, Gemini, GPT, or an open model by selecting the route and deploying to the platform the organization supports. This ensures that as models and vendors go through cycles of birth and death, the harness remains constant, the highest value component of the architecture, and only the neutrality layer changes with vendor differences.
Useful model neutrality preserves the right to exploit model differences.
Claude might be best for a single turn of dialog. Gemini could follow for subsequent turns. GPT might be right for structured output. An open model might handle background work outside the critical path. The value of enterprise AI is letting the business choose the model that fits the workflow, then inspecting and testing that choice inside a neutral harness.
The agent harness is the new lock-in layer.
Better to own it on purpose.
/Contact Us

Modernize your legacy with Focused
Get in touch