Blog
Documentation Drift Breaks Coding Agents
Software documentation tools now shape coding-agent behavior; stale repo docs, AGENTS.md files, and runbooks can send agents into the wrong code path.
Jul 2, 2026

Documentation drift used to be a huge problem for human developers. Waste their time. Now it can cause coding agents to take wrong actions, and even to ship the wrong change.
Previously boring documentation issues get to take on a whole new degree of importance because they can now affect when the wrong change gets shipped by a coding agent.
Software documentation tools used to sit beside the delivery process. They helped onboarding, audits, support, architecture reviews, and the occasional brave soul trying to understand why one module still talks SOAP. Coding agents move that documentation into the execution path. The words in AGENTS.md, CLAUDE.md, repo wikis, rubrics, runbooks, and generated summaries become operating instructions.
LangChain is making this capability explicit with OpenWiki, an open source agent and CLI for generating and maintaining repo documentation for coding agents. As documentation of repo knowledge for agents to execute commands on the repo, the repo documentation is now also the substrate for the agents.
Docs are part of the runtime now
A human can always "fix" the problem with the worst documentation ever. Slow, but true. All a senior engineer needs to do is remember from last quarter how the billing path was moved around, figure out who wrote that offending doc page, check blame, search for the conversation in Slack, and change the docs. Easy peasy.
A coding agent's failures, on the other hand, are insidious because they become commits, even bad ones, with the pretense of doing work. The bad assumption or drift in a document, for example the billing path was in the old service, gets serialized in a diff and it looks productive!
Code documentation AI has become an operational boundary. Yesterday's prompt-cache argument was about how context order became runtime policy. This is the next layer down: the actual repo knowledge being cached, retrieved, summarized, and obeyed.
So while hot files are typically cursed, the simple fact of an agent following a set of instructions for which there is a corresponding set of documentation means the documentation for AGENTS.md and CLAUDE.md for a given project can be maintained as part of the overall repo knowledge. The project README says OpenWiki creates or updates an openwiki/ directory, appends agent instructions, supports openwiki --init and openwiki --update, and includes a GitHub Action template for documentation updates.
Small hot file. Retrieved cold knowledge. Maintenance loop.
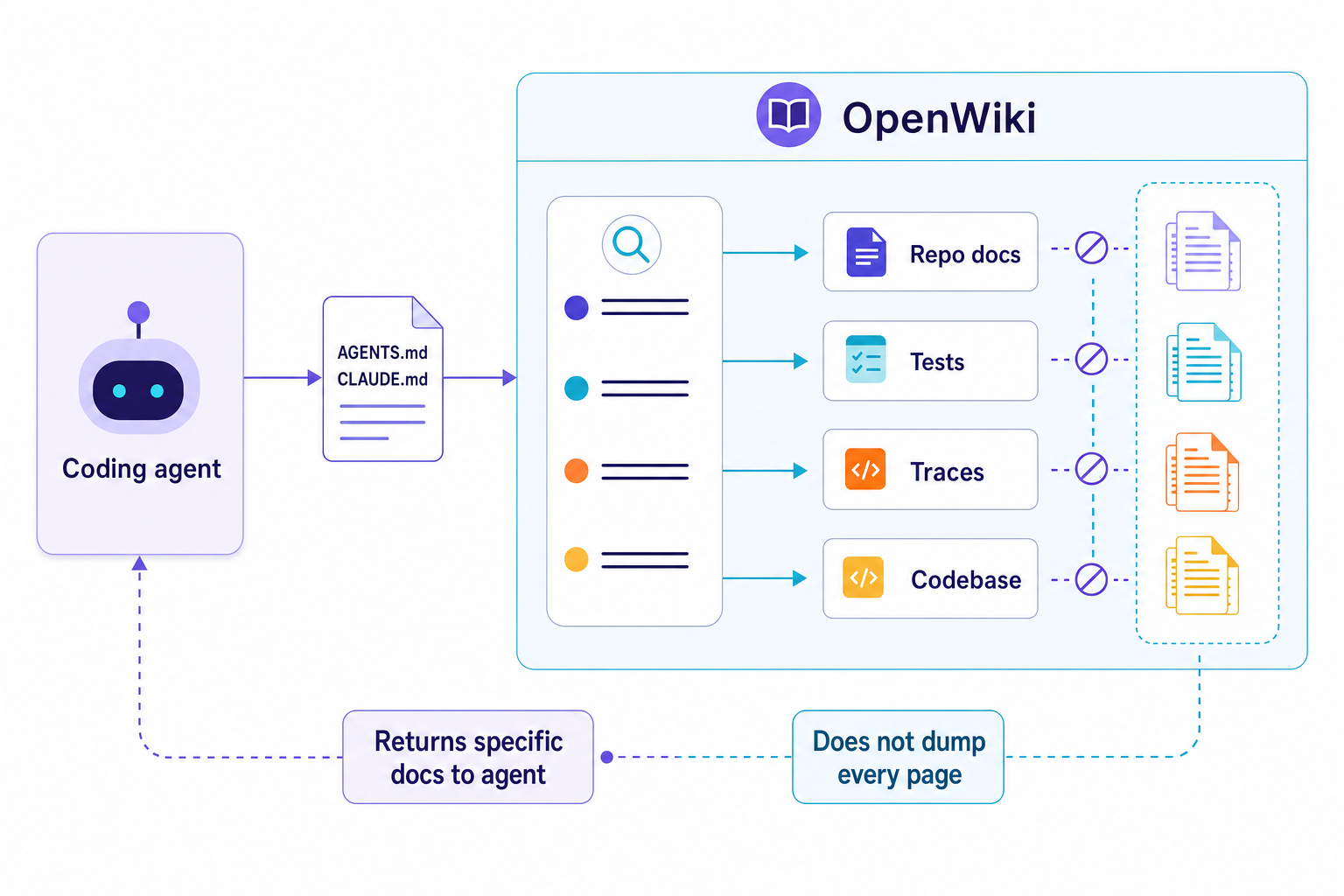
The hot file should contain rules which apply to every run of code such as commands to build, test, and run code; where services and packages are stored; ownership bounds of a service; security constraints to be applied; where a service might be routed to. Every agent run should pay for all the junk that's been added to a file and therefore it should not become a repository for all the architecture decisions that were made along the way.
The giant prompt dump is the lazy fix
Of course, the obvious thing to do with all that knowledge is to include the entire wiki in the prompt. After all, more context must be better, right? But that way lies madness. And not just because of all the noise. It's also that the knowledge in the wiki is likely to be stale in places, and the model will simply latch onto the first relevant-looking paragraph it finds.
Chroma's context-rot work helps to keep the complexity of a task constant while increasing the length of the input, and it finds that LLM performance gets less reliable as the context grows across 18 tested models. The key point for this essay is simply that it is not enough for information to be in context. How that information is presented matters.
Similarly, in large code bases, a huge amount of Markdown can be written down in the end, but the key point is which context is actually hot and is being retrieved, which is being ignored and which is proven to be wrong by a trace or by a test.
The Codified Context paper outlines the same ideas with a slightly different application. In the paper the author creates a 108,000-line C# system with a three-tier context architecture: hot-memory constitution, specialized agents, and a cold-memory knowledge base. This work clearly outlines that documentation that is read by agents is load-bearing infrastructure that the agents rely on for correct results.
This gets software documentation out of the "vibes" category and into the realm of something which can be used in a practical manner. In this case a wiki page used to feed a coding agent is much like a config file and should have similar characteristics: it should have owners, it should change in review, it should be easy to diff, and it should have a way to fail.
So far, I've been framing this problem space within the realm of document quality. Documents are searchable, pleasant to read, versioned, and easy for their authors to maintain. But now that agents read these docs while executing work against repo knowledge, we are asking a sharper question about the software the docs live inside. Can that system serve up the context that an agent needs, with all the properties of good knowledge: provenance, scope, freshness, and feedback from the work it was used for?
Drift is the failure mode
Documentation drift has been around for a long time. The repository changes. The documentation for the codebase does not get updated in time. A new engineer shows up and has to spend a day or two figuring out why a piece of code does not work, and then the team updates the relevant wiki page or documentation for that feature during their next big clean up.
A single stale architecture note can affect a pull request and get engineers mistakenly working on the wrong thing. Stale runbooks can cause an incident assistant to work against the wrong dashboard. A coding agent's running of a suite of tests that the team no longer runs, indeed one they may no longer even have on disk, can result in the agent "successfully" running tests and pushing incorrect implementation bugs into live systems. The code review for an implementation change needs to be able to find these context bugs, today.
This is why agent-facing docs have to be in the same loop as agent evaluation. Once we've established that agent evaluation has to keep running after release, we also have to establish that the agent-facing documentation is in that same continuous loop of work.
LangChain's Pendo case study talks about connecting product analytics, user behavior, session replay, code context, and LangSmith traces to code fixes. Pendo says Novus reached a 90%+ success rate on PM-reviewed evals and moved to live use in days. This is done through their product Novus and LangSmith tying traces to code.
This also means that all the evidence collected during the evaluation needs to update the documentation that was used by the agent to produce the work in the first place. If an engineer or reviewer repeatedly corrects the same thing, for example an agent repeatedly creates code that uses the wrong subsystem for a given task, or uses the wrong convention for something, then that thing belongs in the agent-facing documentation for the repo. Similarly, if a trace runs through a series of tool calls and they detour through an old API during the call chain, the wiki should describe the current migration boundary for that API.
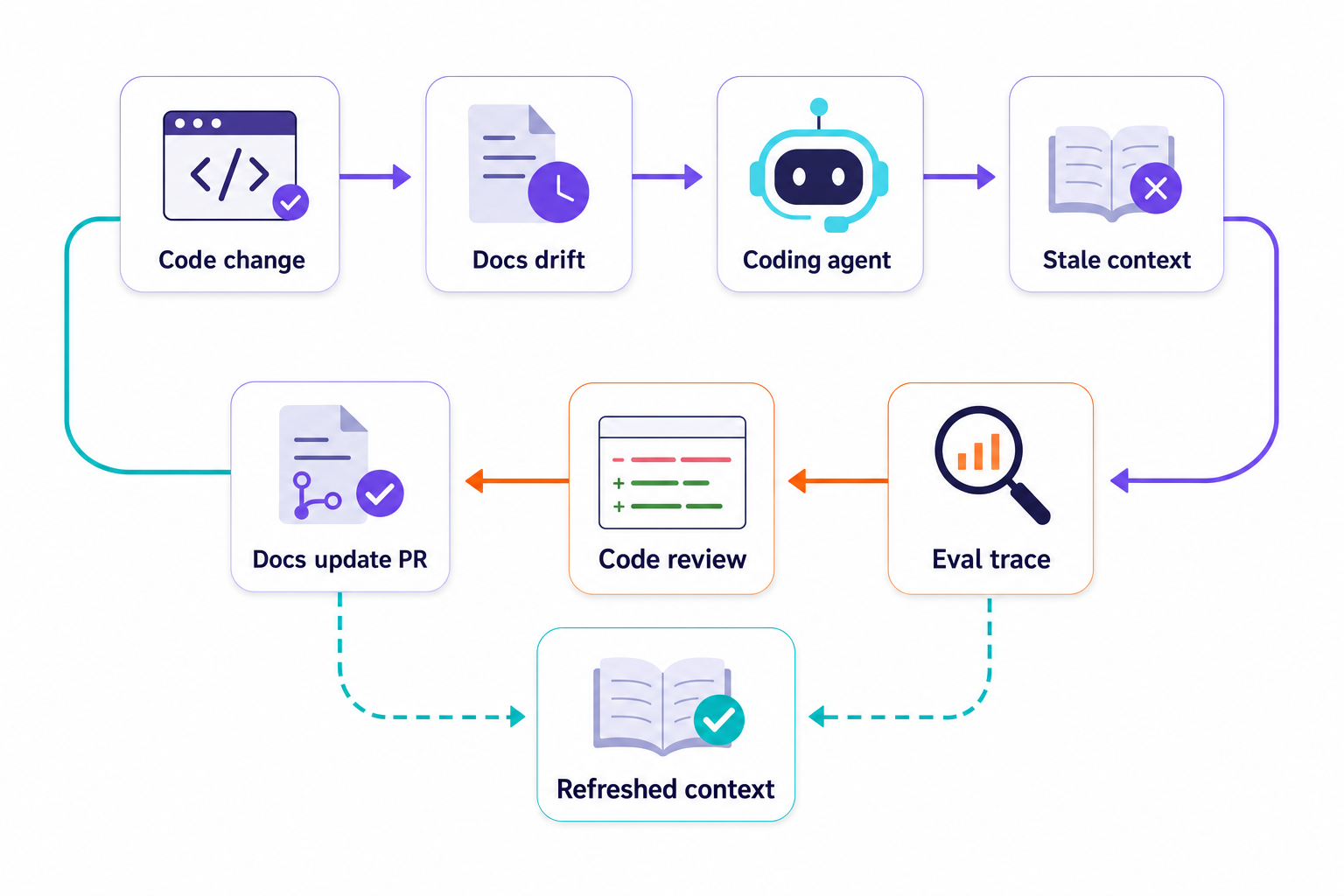
When a documentation update for an agent-facing piece of repository documentation causes changes to the code, meaning it works by having the agent implement something different, then that documentation update should be a pull request.
Faster code makes stale context more expensive
AI-assisted development is producing much more output. Mixpanel reported 50% more pull requests with the same engineering team after AI entered the workflow. The writeup also describes teams connecting MCP and AI coding agents to observability data so agents can inspect traces and see evidence from live changes.
Documentation drift on coding agents gets worse quickly. On every pull request the documentation has to be updated for programming agents, on every new work item, and for every generated change against the wrong premise of stale documentation. Reviewers lose time. Rework loops multiply. CI proves the wrong thing out. The whole system starts sounding busy while being wrong.
This problem manifests as a legacy-codebase problem for generated work, now with a new execution engine. The hard task of a large system is not writing new code, but rather understanding local knowledge: where the bodies are buried, which abstractions are merely formalized and so can be ignored, which tests actually signal real failure, which naming conventions are actually law and so matter, which service boundaries are political. We've already written about legacy codebase knowledge as a team practice and discussed a variety of approaches. The rest of this piece focuses on the new execution engine.
For years we have advocated for teams to write down their legacy codebase knowledge and share it with others on the team. What we failed to recognize, however, was that code written by agents would have its own local context that could be as hard to understand as existing code and which, indeed, would have a lifecycle, would have ownership, could be monitored with telemetry and tested through runtime QA.
Document that can change an agent's code output to be written as code. That's a useful operating rule that treats document the same way as code and so is subject to same scrutiny: written in version control and so can be rolled back.
When doc changes in the agent-facing documentation can affect the output of code generated by an AI-assisted coding agent, this code should also be treated like code: written, reviewed, modified and tracked in a repository, traced back to fixes, released to live systems, etc. It has to be possible to reverse it when the agent gets worse.
Own the agent-facing docs
Ownership is the boring part. Also the part that decides whether this works.
An agent-facing documentation system needs a maintainer model. The platform team can own the mechanism: index, retrieval, templates, tracing, update automation. Product teams should own domain facts. Security should own permission boundaries and forbidden patterns. Test owners should own the commands that prove done. Architecture owners should own migration notes and subsystem maps.
So I described agentic AI implementation running through change control and made the point that because AI is implemented as change to a system, that change must run through records, gates, a rollback owner, and evidence, just as human change does. And similarly, agent-facing documentation deserves to be subject to the same change control as the rest of the system's context that the agent is using to generate output.
The loop can be simple:
- A code change lands.
- The docs job checks whether agent-facing context still matches the touched subsystem.
- The coding agent opens a documentation update PR when drift appears.
- Evals run against representative agent tasks.
- Reviewers can approve the change of context together with the change of code, including a trace, or a failed task.
Agent-readable docs are a separate layer of context infrastructure. They need to be retrievable, citable, testable, and repairable by the humans who own the system.
The fact that documentation drift used to be a tax and with coding agents it becomes a runtime defect is something the team has to own.
/Contact Us

Modernize your legacy with Focused
Get in touch