Blog
Coding Agent Spend Belongs in the Trace
Coding-agent spend becomes manageable when cost is attached to traces, reviewed by engineering, and enforced through gateway policy.
Jul 5, 2026

Coding-agent spend gets weird the second it leaves one developer's laptop.
Here is a specific example where a single feature goes through Claude Code, Codex, Cursor, Copilot, OpenCode and a Deep Agents custom harness before finally being merged in a pull request. Each of these, as standalone tools, can be “perfectly reasonable to buy” with “local usage screen” in front of the team. But then the invoice arrives and the work actually costs something completely different, a question that the engineering lead has to answer.
That question cannot be answered from a vendor bill. It has to be answered from the run.
The problem with “Coding-Agent Bills: Feature Cost in the Workflow of Multiple Coding-Agents” was first discussed on LangChain’s blog in a July post outlines the shape of the problem. As previously mentioned, the feature can interact with several coding agents like Claude Code, Cursor or even Copilot. Each of the mentioned coding agents keep logs of their activities in various formats. As a consequence, it is very difficult to tell the cost of a feature in a workflow. LangChain says, that first a normalized trace of all activities in all root sessions through all turns of interaction of the user with the coding agents in all tool calls, etc. including all the corresponding metadata has to be generated. This trace then can be filtered by session_id, thread_id, by model or provider or even by the names of individual coding tools. The hardest part of solving the problem is the generation of this trace.
The unit is the trace.
The invoice arrives after the damage
Finance sees an invoice after it has gone through the run process. Engineering sees a loop that is still costing money.
The waste that coding-agents produce is behavioral waste. That is to say, it is the same patterns of suboptimal behavior that other agents produce. Time and again an agent will keep retrying the same failing test. Every time it goes to generate some text for a lint fix it will use the most expensive model available. A monolithic repository summary will be included in every interaction turn. Slow tools will be called to perform tasks only to be given very vague error messages. The same tool will then be called again and again until eventually another agent is called in to help debug the mess. Eventually a bill will be generated for all that was spent, which will tell the finance department how much was spent. The trace of all the calls, etc, generated while that bill was being incurred will reveal the precise sequence of tool calls that resulted in the bill having that amount.
Agent spend is a runtime signal. Coding agents make that signal less abstract. Spend gets tracked against a repository, branch, commit, pull request, developer, team, model, provider, tool, and session. That abstract finance problem scattered across product dashboards becomes an engineering problem once the fields coalesce into a single session trace.
Engineering problems can be fixed.
Many of the classic cloud cost playbook steps are still widely adopted by organizations building out FinOps practices, as laid out by the FinOps Foundation FinOps Foundation. Cost per token, highly volatile pricing for cloud compute and memory, particularly for GPU instances, as well as usual quotas on consumption of cloud resources, tagged resources to group costs by application or team, and real-time finance metrics that track to business outcomes. Coding-agent spend is typically treated as spend that runs in loops and programs, as opposed to being treated as spend that can be represented in spreadsheets. Thus a quota is only hit when spend hits a line, and a trace shows what led to that line in the first place (e.g. bad retry logic, too much context in function, missing cache hit, poor model routing).
Vendor dashboards answer local questions
Tool dashboards are useful until they become the only record.
Claude Code has local usage statistics at /usage, and Anthropic's cost guidance covers team spend limits, context compaction, model selection, MCP overhead reduction, hooks, skills, and subagent delegation. Fine operator surface for Claude Code. It still does not tell the team how much a PR cost after Claude Code, Codex, Copilot review context, and Cursor all touched it.
LangSmith Codex tracing feature for Codex tracing logs: agent turns, model metadata, token usage, tool calls, and subagent threads. OpenCode tracing OpenCode tracing logs: session root runs, assistant turns, nested tool calls, tool errors, time, attachments, subagent activity, token usage, and thread or session ID metadata for root and child sessions. Note that the Chat feature in Copilot exports OpenTelemetry spans where the invoke_agent, chat, and execute_tool spans contain total token usage, model data, and subagent context that gets propagated through tool execution. The plugin for the Codex tracing feature in LangSmith’s Codex LangSmith's Codex tracing plugin. Copilot Chat can also export OpenTelemetry spans Copilot Chat can export OpenTelemetry spans.
More importantly, the larger ecosystem is starting to generate trace-like evidence while the output of individual tools from session to session can be quite different from one another. Unlike a dashboard, this would be a normalized log of an entire coding session that makes full use of all of the single tools as well as all of the intermediate functionalities in between.

LangSmith’s coding-agent metadata contract lists the shared fields by name instead of relying on observability to discover them. In addition to global identity fields like ls_agent_kind, ls_integration, ls_agent_runtime, thread_id, and ls_trace_schema_version, the contract lists run types: root, llm, tool, subagent, and interrupted. It also lists repo fields the runtime may expose: repo, branch, commit, working_directory, provider, model, tool, and subagent.
That contract is boring in exactly the right way. Boring fields make cost queryable. Boring fields let an engineering manager ask which repo burned spend last night, which agent runtime did it, which model got selected, which tool failed, and which team owns the pattern.
The same thing is true for spend. Agent observability runs on a stable conversation or session ID because that ID lets traces, tools, queues, APIs, evals, and incidents line up. Cost should line up on that same spine, not show up as line items with no causality.
Cost without behavior is accounting
A cost report that cannot point at behavior is just accounting with better charts.
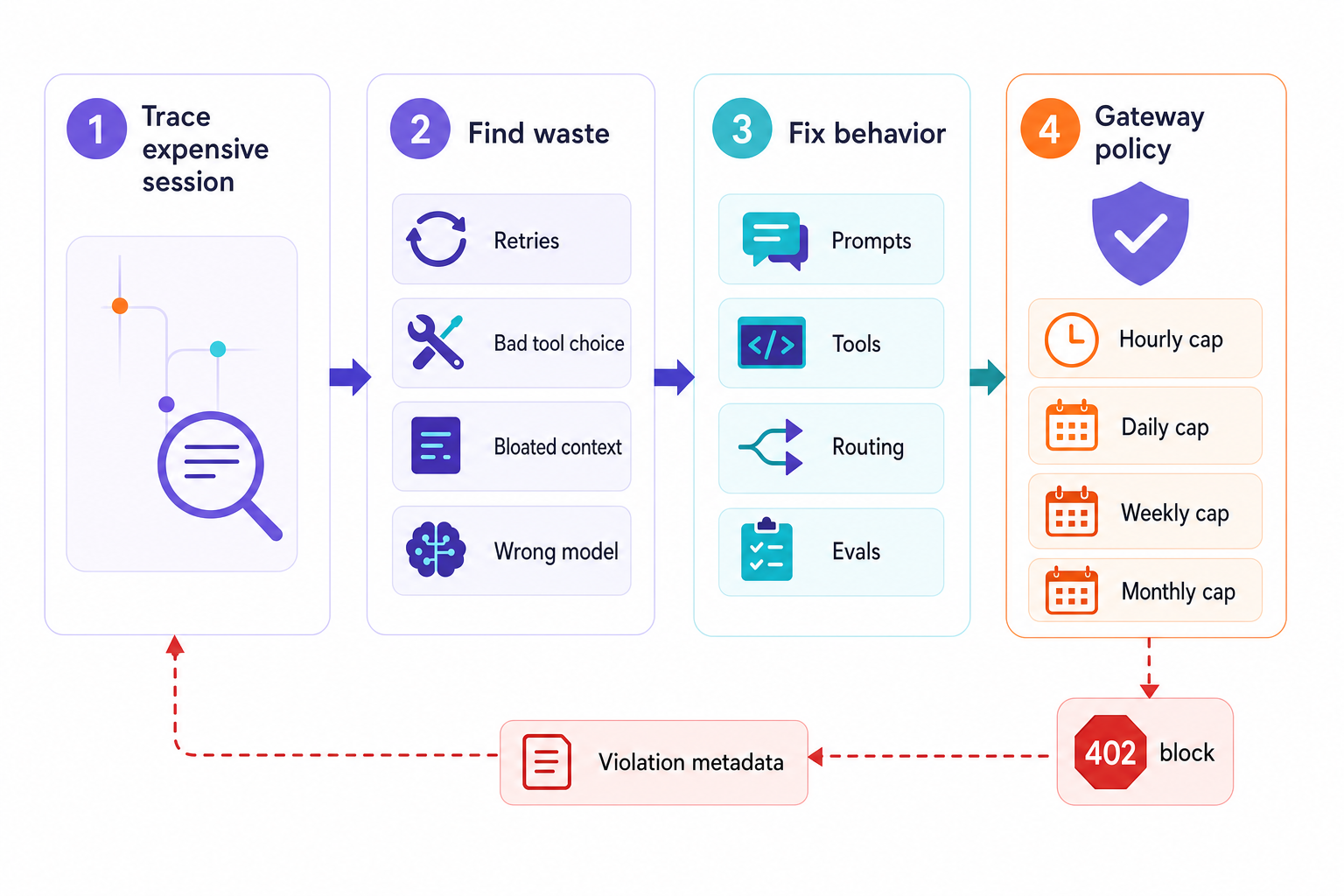
One thing I would really like to see reported in a lot of detail, are all of the ways a coding-agent session could go over budget. That report could be a simple list of causes and fixes for each. The number for each cause would be the smoke for that area, and then a trace of the session in the room would show where the extra cost occurred.
LLM cost management is a behavior problem, not just a finance problem. Cut out the irrelevant stuff. Simple stuff should be done by cheaper models. Cache the constant stuff. Deciding which tool to use for a particular task. Fixing the docs that cause an agent to fail for a particular task. Trimming the subagent path that reads and re-reads same files for a particular task. That’s a finance system approval for a budget for this. Here’s a trace for that approved budget.
For clients of the agent platform, it matters to tie out spend on agents to engineering outcomes. A spend dashboard is only so useful if no one can connect the spend to outcomes such as did the agent make the team faster, did it create useful PRs, did it take review work off the team’s plate, did incidents go up or down, can we stop those runaway-until-breakfast sessions next time. Building a run record, not just a screenshot, is the only way to get there.
Gateway policy closes the loop
Visibility without a control boundary turns into monthly regret.
LangChain’s internal LLM Gateway rollout is an interesting example because the company tied spend to live control. Their writeup describes how one heavy coding-agent user could have spent thousands of dollars per week before anybody noticed. By putting coding-agent calls through Gateway, they set monthly, weekly, daily, and hourly budgets, then tied spend to traces, users, keys, agents, model calls, and failure modes. That is the correct sequence: see the run, fix the behavior, cap the boundary.
Documentation for the Gateway that this sits in front of is here: The LLM Gateway sits between agents / clients and model providers. It holds the secrets for the various providers, authenticates the caller with a LangSmith API key, evaluates spend and redaction policies for that caller, proxies the request to the upstream model provider, and traces the return back to LangSmith. The spend policies here Spend policies are organized by organization, workspace, API-key, or user, and can be limited to a monthly, weekly, daily, or hourly period. When a request is blocked (i.e. it would exceed budget), it returns a 402 with the spend-policy violation as trace metadata for the request that was issued. Gateway docs
A critical product decision here was to make policy violations trace events as opposed to just finance events that got blocked. But the block is part of the same evidence stream as the prompt, the model call, the tool results, the repo metadata, and the agent runtime.
This is where spending authority moves into the runtime. A coding agent is spending shared budget on behalf of a person, team, repository, and task. Policy has to sit near that action: approvals, budget caps, provider credentials, redaction, trace metadata, and issue creation.
Just setting a monthly limit is not enough. One also should consider hourly and daily limits for a single command run over night for example. User / API-key limits to catch misuse through integration paths that a team did not think to budget for. Workspace limits to stop experiments in live environments going out of control. And finally organization level caps to put a roof on all of this, where each of these limits describes a different way to define ownership.
The first version can be simple
The first version does not require a grand platform migration.
The trace should contain enough information to correlate the money spent with the work done by the engineers. The trace fields that need to be included in the trace in order to use them in the dashboards are the following trace fields that join spending with work done by engineers: session ID, user, team, repo, branch, commit, PR, agent runtime, integration, model, provider, tool name, token usage, cost, status and error. Subagent IDs can be added to the trace later when delegation starts to surface in traces. Also environment and service tags can be added to the trace later when coding-agent work is tied to runbooks or other work done by the infrastructure coding teams. All of the above fields should be included in the trace before they can be used in the dashboards.
Then add three questions to the weekly engineering review.
Which coding-agent sessions were expensive and useful?
Which sessions were expensive and stupid?
Which stupid session can be prevented next week?
Not glamorous but useful to know. This review will find out whether the Context Packs, repo documentation missing repo documentation etc are up to par. It will find out if the agent instructions prevent tool spam, if the model defaults are current. It will also find out whether people are using coding agents for work that should really be scripted instead. And then there are the useful expensive sessions. Deep code archaeology costs money and while a multi-hour migration agent may cost a lot of money for a multi-hour run of work, a clear outcome and a traceable run can still be worth it.
The control plane conversation continues. As coding agents become shared engineering infrastructure, registry, identity, policy, monitoring, cost, approvals, and retirement start to live together in the same operating estate we covered in Enterprise AI Agents Have a Control Plane Now.
Cost is part of the execution record
The cost of coding agents is not a side channel. It is part of the execution record for how software changed.
The uncomfortable truth here is that agent spend is someone’s engineering responsibility. Not in the performative sense of saying “use fewer tokens”, but in the normal operating sense of owning the fields, the trace shape, the gateway policy, the retry loops, and the review to confirm that very expensive work was worth it.
This is the operating model I trust: it does not shame developers for using agents, it does not imply that the cheapest model is the best. Spend should be managed the same way that good teams manage latency, errors, deploy risk, and incident noise. The signal should follow the execution path.
The invoice still matters. It just shows up too late to be the source of truth.
/Contact Us

Modernize your legacy with Focused
Get in touch