Blog
AI Agent Observability Runs on Conversation IDs
Agent observability gets useful when one conversation ID follows the agent through model calls, tools, APIs, queues, databases, and eval loops.
Jul 3, 2026

Agent observability gets weirdly polite at the exact moment it should get nosy. It records the model call, stores the prompt, counts tokens, and then loses interest right when the agent starts touching software.
That makes the trace look clean and the incident feel impossible.
The failure rarely lives inside the LLM span. Honeycomb's Agent Timeline instrumentation guide says a GenAI span can be any work the agent caused: model calls, tool calls, handoffs, downstream services, database queries, and background jobs. That is the right unit of observation. The agent is runtime software making choices and causing side effects.
The conversation ID is where that reality starts to show up.
The trace breaks where the work starts
LLM-call logging feels useful because it gives teams an artifact. The prompt was this. The response was that. The model returned tool calls. Fine.
Then the tool calls a service. The service writes a row. A queue worker picks up the job. A downstream API retries. A database query times out after the agent has already answered the user. The model trace stays green because the trace lost the work.
The older observability mindset matters even more with agents. Logs answer the question a developer guessed in advance. Traces let the team follow the shape of the system after the weird thing has already happened. Agent systems add a worse version of the same problem because the execution path is partly selected at runtime.
A token count will not explain why the refund tool wrote to the wrong account. A prompt transcript will not explain why a sub-agent retried the same API call through two paths. A model latency chart will not explain why a background reconciliation job created the user-visible failure.
The agent caused work. The trace has to follow the work.
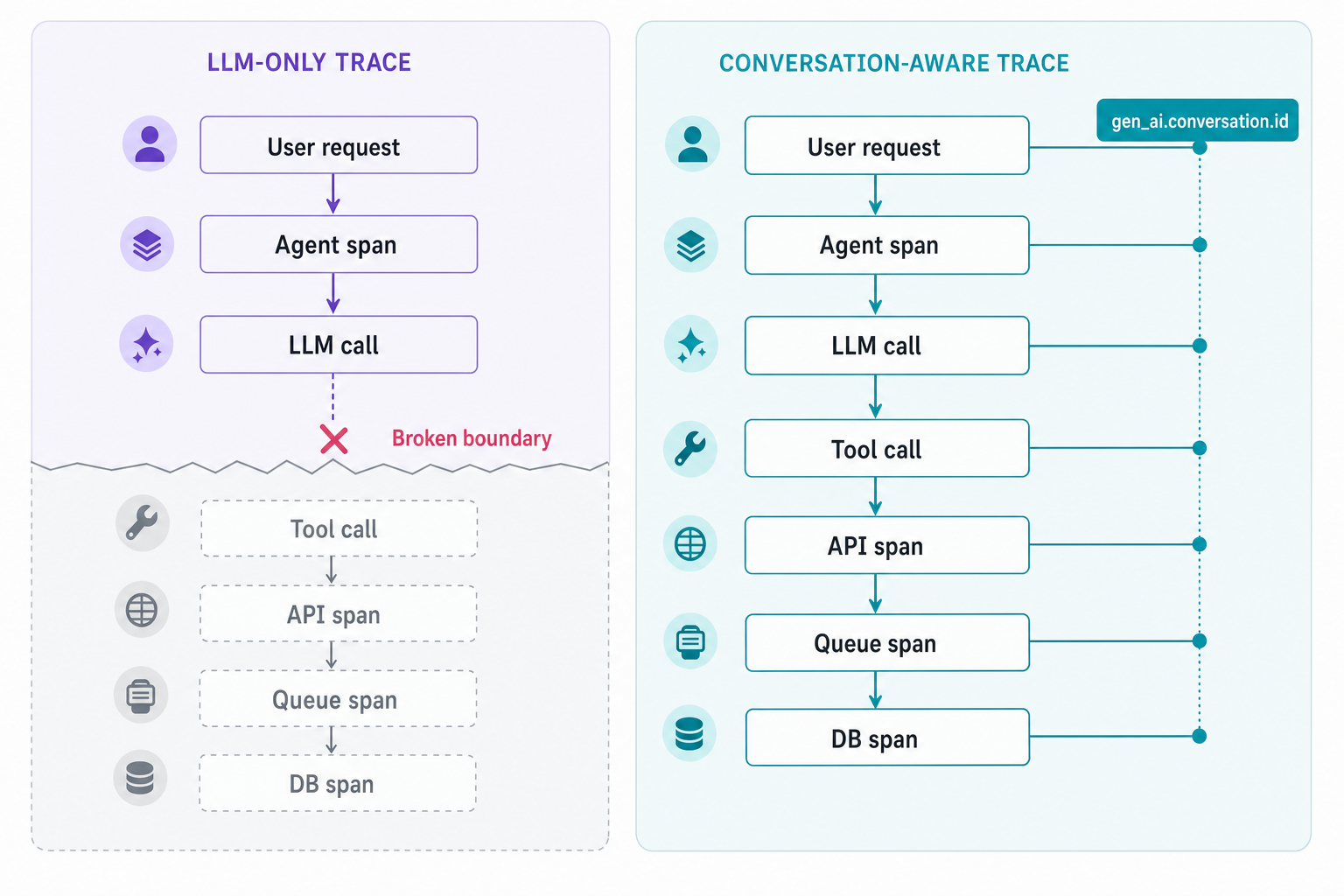
Conversation ID is the live unit
Honeycomb's docs make the minimum viable shape pretty plain. Agent spans need gen_ai.conversation.id, gen_ai.agent.name, and gen_ai.operation.name so the timeline can group spans into a session, attribute work to an agent, and distinguish operations like chat, execute_tool, invoke_agent, and invoke_workflow inside the Agent Timeline.
The phrase reads like metadata, but it decides whether the team has a trace or a receipt.
The trace ID describes one distributed execution. The conversation ID describes the user-facing unit of work across traces, services, and turns. A support agent classifies a request, fetches account state, hands off to a billing agent, and waits for a queue worker before it sends the final response. Those steps can land in different traces. The customer experienced one conversation. The system created a pile of spans.
Without gen_ai.conversation.id, the pile stays a pile.
There is one easy mistake here: do not fake the identifier at the leaf. The OpenTelemetry GenAI agent-span conventions say gen_ai.conversation.id should be populated only when a real identifier is readily available, and should not fall back to a new UUID, trace ID, or hash of request content when no conversation identifier exists. That guidance matters. If every service invents its own conversation ID, the attribute becomes confetti with better naming.
Mint the conversation or session ID at the boundary where the product understands the interaction. Pass it inward. Attach it to agent spans, tool spans, HTTP client spans, queue jobs, DB spans, and eval events. If a downstream service cannot carry it, that service is where the trace goes blind.
We have written before about trace context crossing the tool boundary. Conversation IDs add the user-facing thread across those technical boundaries. Trace context keeps parent-child relationships intact. Conversation context lets the team ask, "show me everything this agent conversation caused." Both have to survive the tool call.
Span ancestry is not paperwork
LangSmith's OpenTelemetry docs include a nasty little failure mode: a child span whose parent never reaches LangSmith can be accepted with a 200, buffered, and then dropped later if the parent never arrives because the OTEL endpoint processes spans asynchronously. That is exactly the kind of observability bug that looks fine in CI and ruins an incident review.
The system said yes. The evidence vanished.
This is why partial agent tracing is dangerous. A team can have beautiful traces for the orchestrator and still lose the tool execution. Another team can export the tool service and lose the parent agent span. Sampling can keep the cheap part and drop the causal root. A vendor console can show green ingestion while the useful run never materializes.
Agent observability has to be treated as an export contract.
Every service that participates in the agent path needs to agree on ancestry, conversation ID, sampling behavior, redaction rules, and ownership. That includes boring services. Especially boring services. Billing APIs, CRM updates, search indexes, authorization checks, queue workers, and database writes are where the agent becomes real software. The model span is just the planner with a transcript.
This is why agent monitoring as infrastructure is the right operating model. The app team cannot sprinkle tracing on the agent wrapper and call it done. The platform has to make propagation easy, collectors safe, sampling legible, and missing-span failures visible.
Agent names decide accountability
Multi-agent systems make the naming problem uglier.
Honeycomb's docs warn that each agent needs a unique gen_ai.agent.name, and that sub-agents should not inherit the parent agent's name because duplicate or missing names make investigation impossible inside a grouped agent timeline. That sounds fussy until the first live handoff fails.
The billing agent invoked the policy agent. The policy agent called a CRM tool. The CRM tool wrote a field that changed the next user message. If every span says support_agent, the team has a transcript and no ownership record. If every sub-agent gets a stable name, invoke_agent becomes a runtime transfer with evidence attached.
That is the same boundary we hit in agent handoffs as runtime state. Handoffs are not vibes. They are ownership transfers. The receiving agent needs state. The sending agent needs a receipt. The trace needs to show who acted, who delegated, who observed the result, and which name owns the failure.
Agent names are also release artifacts. A renamed agent can break dashboards. A reused name can hide a new implementation behind an old label. A temporary experiment name can leak into live traffic and turn a week of traces into archeology. Name the agent like a service. Version the behavior somewhere else.
Prompts are data with a governance boundary
A useful agent trace wants the thing security teams hate storing: prompts, responses, tool arguments, tool outputs, retrieved context, and evaluation notes.
That tension will not go away. It has to be designed.
Honeycomb recommends storing full prompts, chat history, and completions as span events because they may be large or contain sensitive data, while the docs call out that an OpenTelemetry Collector can filter or redact them before ingestion when events carry prompt and completion content. LangSmith documents the same architectural move: route application traces through an OpenTelemetry collector, apply transform rules that redact sensitive span attributes, and forward sanitized traces to LangSmith through a gateway-style redaction path.
That collector draws the line between operational evidence and data sprawl.

The safe pattern is boring: keep low-cardinality routing attributes on spans, put sensitive prompt and completion payloads in events or controlled attributes, redact at the collector, and make the redaction policy testable. The team should know which fields are kept, which fields are dropped, and which fields are transformed before they hit a vendor or shared backend.
There is another boundary hiding here. LangSmith's distributed tracing guide warns that langsmith-trace and baggage headers should be accepted only from trusted internal services, not public callers, because they are consumed as trusted tracing context and can influence how runs are recorded if a gateway passes them through. Good. Trace context is not harmless just because it is metadata.
A public request can carry lies. Internal propagation can carry evidence. The gateway has to know the difference.
The trace should feed control
The point of agent observability is not a prettier incident screenshot.
Candidly's LangSmith writeup is useful because it shows traces turning into a control surface. Their Cait financial-planning agent moved from post-hoc conversation evaluation toward turn-level state inference. The labeling pipeline reached 92.3% agreement with a human-labeled LangSmith dataset, and trace-derived features predicted resolved versus abandoned conversations with 0.90 AUC in the Candidly case study.
That is the loop worth copying.
Live traces should become regression cases, eval datasets, policy changes, routing fixes, and release gates. A conversation ID makes that possible because it lets the team collect the entire causal path, not just the final answer. The trace shows which tool ran, which state changed, which sub-agent owned the handoff, which prompt version ran, and which downstream span failed. The eval can score the behavior against the actual evidence.
That is also why AI agent evaluation has to steer the harness. The trace cannot stop at telemetry collection. If a live conversation exposes a broken handoff, the fix should not be a screenshot in Slack. It should become a test case and a control.
The best traces become software.
Instrument the boring path first
The first pass does not need a grand observability platform. It needs a clean propagation contract.
Start with the product conversation or session boundary. Create or retrieve the real conversation ID there. Pass it through the agent runtime. Attach it to the root invoke_agent span. Carry it into LLM calls, tool execution, service calls, queues, and database work. Add gen_ai.agent.name at every agent boundary and use stable names for sub-agents. Set gen_ai.operation.name with the closest standard value instead of inventing labels for basic operations.
Then break the system on purpose.
Force a tool timeout. Drop a parent span in a staging environment. Send a request through a queue. Trigger a sub-agent handoff. Verify the timeline still tells the story. Check that the collector redacts the fields it claims to redact. Confirm public trace headers get stripped at the edge. Find the first span where the conversation ID disappears and fix that before buying another dashboard.
This work feels unglamorous because it is. Also because it is the part that decides whether the next incident review has evidence.
AI agent observability follows what the agent caused. The conversation ID is the thread. Pull it through the stack, or accept that live systems will keep handing back neat little model traces while the actual failure happens somewhere else.
/Contact Us

Modernize your legacy with Focused
Get in touch