Blog
What to Do When LLMs Hallucinate
Chatbots like ChatGPT run on Large Language Models that use statistics to figure out what words to string together. Sometimes they're wrong — and they don't know it. Those convincing but incorrect answers are called hallucinations. So how do you deal with them? From data cleaning and prompt engineering to LLM settings and source citations, here are the practical levers you can pull to improve accuracy.
Aug 21, 2023

Chatbots are the cool new thing nowadays. ChatGPT went viral and has given this area of AI research a huge boost in the public eye. Chatbots like ChatGPT run on at least one Large Language Model (LLM) to produce text a human can understand. They use statistics to figure out what words to string together to answer questions or complete tasks.
Since LLMs use math to figure out how to answer your questions, you can imagine that sometimes they are wrong. Context or meaning can get lost in translation, especially if you ask questions using incomplete thoughts or sentence fragments. They don't know they're wrong, but they will give you pretty convincing answers that seem right. Those convincing but wrong answers are called hallucinations.
So how do we deal with hallucinations when they occur? In short: we loaded documentation from Focused Labs' Notion/wiki, we gave the LLM the information, and then we asked it questions about the info we loaded. We're not training the LLM, but rather giving it more information so it can answer questions about Focused Labs. The chatbot's accuracy varied; it was accurate sometimes and inaccurate at other times (but boy it sounded super convincing). So, how did we go about trying to solve this issue?
Iterate on Small Changes
To gauge the accuracy of our chatbot, we came up with a list of both specific and broad questions to ask the model. This set of questions enables us to determine if we are improving as we make small changes. We ranked each answer from our chatbot on a scale of 1-5 for correctness.
When an LLM tries to summarize the information, sometimes it gives partially correct answers. For instance, we asked 'What are the Focused Labs' values?' The chatbot correctly answered "Listen First", "Learn Why" and "Love Your Craft." However, the model also returned three additional concepts it interpreted as values. We'd rate an answer like this a 4. The LLM had the right answer, but it gave additional information.
Asking the same questions repeatedly can become monotonous and repetitive. Using our set of questions provided a scientific method to evaluate the effectiveness of the changes we made. If the answers improved, we would keep the change. Otherwise, we would back it out or iterate on it until it proved worthwhile.
Small changes can drastically change answers, so it's better to do a little at once rather than implement a bunch of changes and hope they all improve the results. Now, let's talk about what we can change when we create a chatbot to help improve results and eliminate hallucinations. The majority of these items are low-hanging fruit, so pretty easy to implement.
Provide More Data on the Topic
LLMs excel at processing written language only when the language describes complete thoughts rather than incomplete ones. If the documents consumed are poorly formed/formatted, or the content consists of incomplete thoughts, then the LLM might have trouble interpreting the content of the document uploaded.
For instance, we have a page on our website with all our employees' names and some of their interests. When we asked the LLM about this page, it struggles. The LLM has trouble interpreting the data on the page because it is not formed in a way it can understand.
To improve this, we have a couple of options:
- Clean up the data.
- Give it more information on the topic in question so it has more data to craft a response.
We'll talk about cleaning in a minute. Giving the LLM more information about a topic can help it make sense of the data it has already consumed. It's like writing a research paper… you find lots of information to help reinforce a given point. The LLM will fill in any blanks if it has additional information. We're doing the same with the LLM so it can better understand what we've given it.
Clean Your Data

For the model to understand the data we're giving it, it's a good idea to tidy up a little bit. Many resources suggest a lot of different types of cleaning, but we took a basic approach and still improved the accuracy of the LLM's responses. Removing punctuation (e.g. asterisks, trademarks ™, and line breaks) can help.
For our Notion data set, we also removed emojis. This gave us the biggest boost to response accuracy. The models don't know how to interpret emojis so it can confuse the model. For example, we asked the LLM when the company onsite event takes place. The model gave us the start date but not the end date because there happened to be emojis involved. We obtained the full date range for the event after removing them.
When cleaning data, it's important to ensure the meaning of the data does not change. Some sources suggest making the dataset lowercase, which is not uncommon when training an LLM. However, we found it changed the meaning of the data. Proper nouns ended up being ignored and it negatively impacted our results. To better understand how a small change can affect your results, it's important to take small steps and evaluate the impact of each change.
Better Prompt Engineering
Instructing the LLM on how to answer questions can lead to better results. This is how we can get the LLM to use "reasoning". This process is called prompt engineering.
We take the user's question and then wrap a prompt around it. Something as simple as "Think this through step by step when you answer the following question: <the user's question goes here>" can yield better results than giving it the question alone.
Depending on the chatbot being built, you can use a variety of prompt engineering styles:
- Few Shot Prompting: Giving examples to the LLM on how you want questions answered will allow it to create better results. The model can gain a better understanding of the task by studying the examples.
- Instructor-Based Prompting: Asking the LLM to assume a persona will also yield better results. For instance, if you ask the chatbot to answer a question about a coding project, you'll probably want it to give deep technical answers to a software engineer but perhaps a more summarized version for a project manager. To do this, you can ask the user to input their role in a company and use the role to inform the LLM on how to answer the question.
- Chain of Thought: Asking the LLM to think things through step by step before answering the question. This forces it to reason its response as it comes up with an answer.
- Tree of Thought: This particular style of prompting allows the model to reason out answers and correct errors in the response. To arrive at the final answer, you can ask the LLM to generate three different answers, compare them, and use the data embedded in the model to determine the most accurate one. This helps with logic-based questions.
- Society of Mind: So if one LLM can get to a response and correct its errors using reason as in Tree of Thought, what happens if we add another LLM into the mix? For instance, you could ask Bard and ChatGPT the same question, then funnel those answers along with the question to yet another LLM and it will often correct any mistakes made. Using the Society of Mind prompting is more powerful than Tree of Thought prompting, but it also requires more resources to run.
Of all the items listed in this article, experimenting with different prompt engineering styles can be one of the more time-consuming due to the amount of necessary experimentation. Using different prompt engineering styles can have a significant impact on the results returned by the LLM.
Test Different LLM Settings
When creating an LLM there are a lot of levers you can pull to yield better results. You can change configuration settings like the temperature or the top k results returned. Let's go into a few different settings and talk about those:
- Temperature: This setting tells the LLM how creative it can be with its responses. The scale is set from 0 to 5, where 0 gives the same output every time because it's more strict. 5 could give you some pretty fantastical answers. For our chatbot, we've used 0 and 0.5 for the most part. If the temperature gets too high, the LLM can stray off-topic and enter the realm of fantasy. Maybe you want that if you're building an LLM to create Dungeons and Dragons characters, but for a business setting, I'd set it no higher than 1 for the best results.
- Limiting the Number of Tokens: When querying an LLM, you can limit the number of tokens returned. Tokens are the way a model interprets words, and limiting this number will force the model to choose more statistically accurate results when generating a response.
- Top K: The LLM picks the top k tokens sorted by probability to determine what token comes next in the response, where k is the number of tokens to return as options. If the top k is set to 1, it's always going to choose the top-ranked token. If it's set to higher than 1, then it'll look at multiple tokens before making a decision of which to choose. A pretty common value for this is 3.
- Swapping out the Model: Different LLMs are good at different things. OpenAI initially had a model known as Codex, which excelled at interpreting code-related topics (code interpretation capabilities are coming for the GPT 4 model). Whereas some models are better for a chatbot, others might be more optimized to translate from one language to another. If you're building an app with multiple purposes, then you might want to investigate which models suit each purpose the best. To achieve the best results for a given task, it is common practice to utilize multiple models to perform different functions.
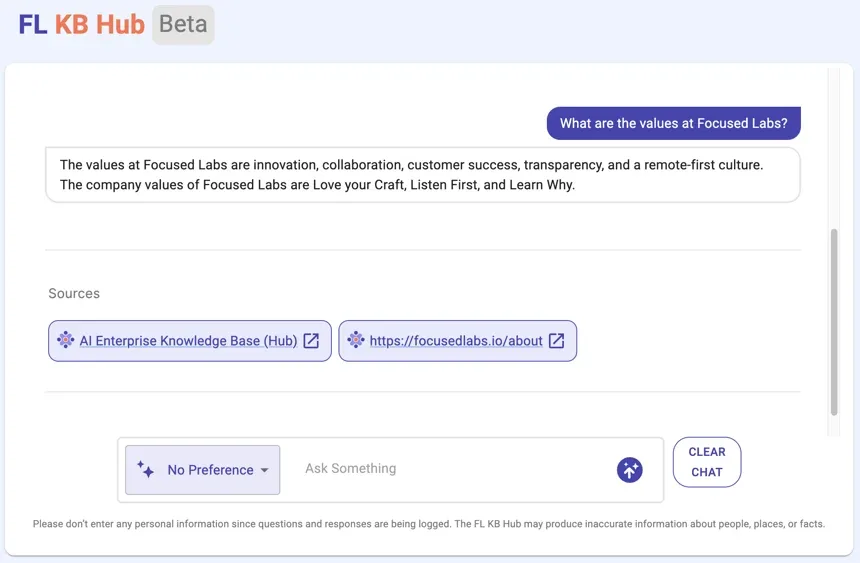
Cite the Model's Sources
Establishing trust with users who interact with a chatbot is crucial. To ensure transparency, it's best to cite the documents used to inform an answer since LLMs can be wrong on occasion. This allows the user to go review sources and verify the results are accurate. Citing the sources allows users to verify the information returned and build trust, although not everyone will check them.
Audit User Input
Once a chatbot is released for production, it's important to assess whether the user perceives its responses as accurate. One way is to add a feedback mechanism to let you know what is going on. Whether that be a way to flag the response or a way to contact customer support.
This feedback can let you know what issues there might be with the LLM. If the chatbot repeatedly answers a specific topic incorrectly, the data for that topic can be examined. Perhaps it has malformed data and needs to be cleaned up, or more information needs to be embedded for the LLM to reference. User input will allow us to focus on any particular dataset that needs to be modified.
Acceptance: LLMs Are Occasionally Wrong
I found it interesting in the AI community most people do not worry about their chatbot hallucinating once they have it to a point where it's answering the majority of questions correctly. The AI community understands that models aren't perfect and that they occasionally make mistakes. It is impossible to guarantee that the chatbot's answers will be correct 100% of the time.
Does the general public know this as well?
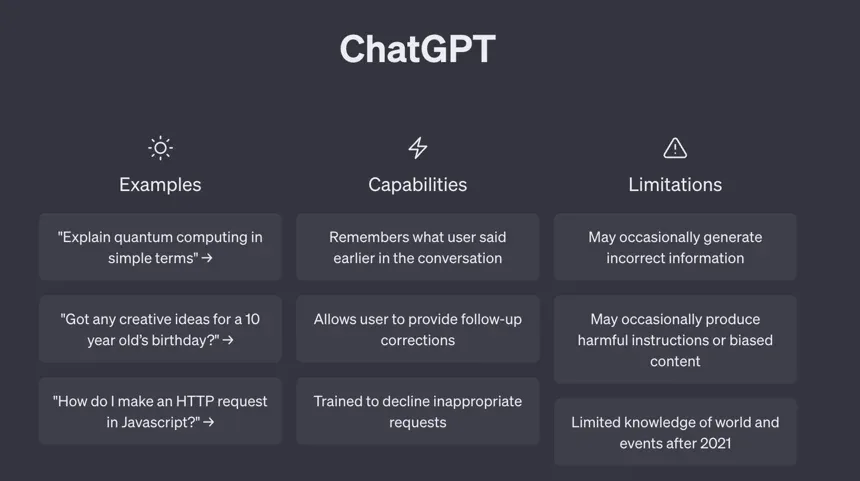
ChatGPT informs the user that it may provide inaccurate answers, and welcomes feedback. Perhaps developers should add copy to let users know the chatbot isn't perfect. However, that is a decision each development team should have to make for themselves.
The Levers to Eliminate Hallucinations
Numerous techniques exist to tackle and mitigate hallucinations. Providing more data in embeddings, cleaning the data, prompt engineering, citing sources, LLM settings, and gathering user input will allow you to gain a bit more control over how your chatbot responds.
When iterating on changes, make sure to take small steps so you know what changes are most effective for the application. Although there is still the possibility of inaccurate responses, we can expect fewer concerns in the future as models continue to advance.
Prompt engineering currently serves as a great tool. However, models like GPT4 are being trained to create their own prompts. Eventually prompt engineering will become a thing of the past. AI Technology is rapidly evolving and changing every day. Experimentation is the key to creating successful AI solutions. Embrace the tools provided, continue researching new technology as it comes out, and you'll be on your way to creating an AI solution you're happy with.
What's Next
If you have an AI development project and would like some expert help from our Focused Labs consultants, complete our Contact Us form and we will have a human chat.
/Contact Us

Modernize your legacy with Focused
Get in touch