LangChain
Your RAG Pipeline Hallucinates Because It Never Checks Its Own Work
Build a corrective RAG pipeline with LangGraph that grades retrieval quality, rewrites bad queries, and generates cited answers.
Jun 30, 2026
Your team ships a documentation chatbot. It retrieves chunks, stuffs them into a prompt, and generates an answer. Demo day goes great. Then a customer asks "what's the rate limit for the batch API?" and the bot confidently answers "10,000 requests per minute" — citing a doc about a completely different API. Nobody catches it because the answer sounds plausible.
This is the core failure mode of naive RAG: the retriever returns something, the generator uses it, and nobody checks whether the retrieved context actually answers the question. The fix isn't better embeddings or bigger context windows. The fix is a pipeline that grades its own retrieval, rewrites the query when results are poor, and refuses to generate when the context doesn't support an answer.
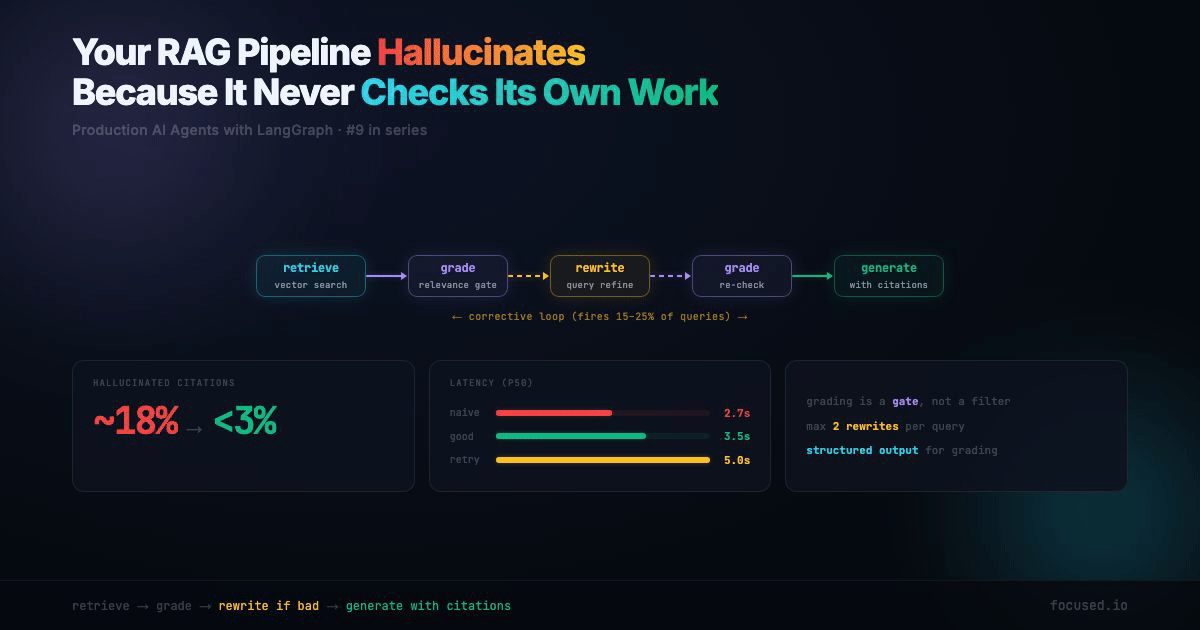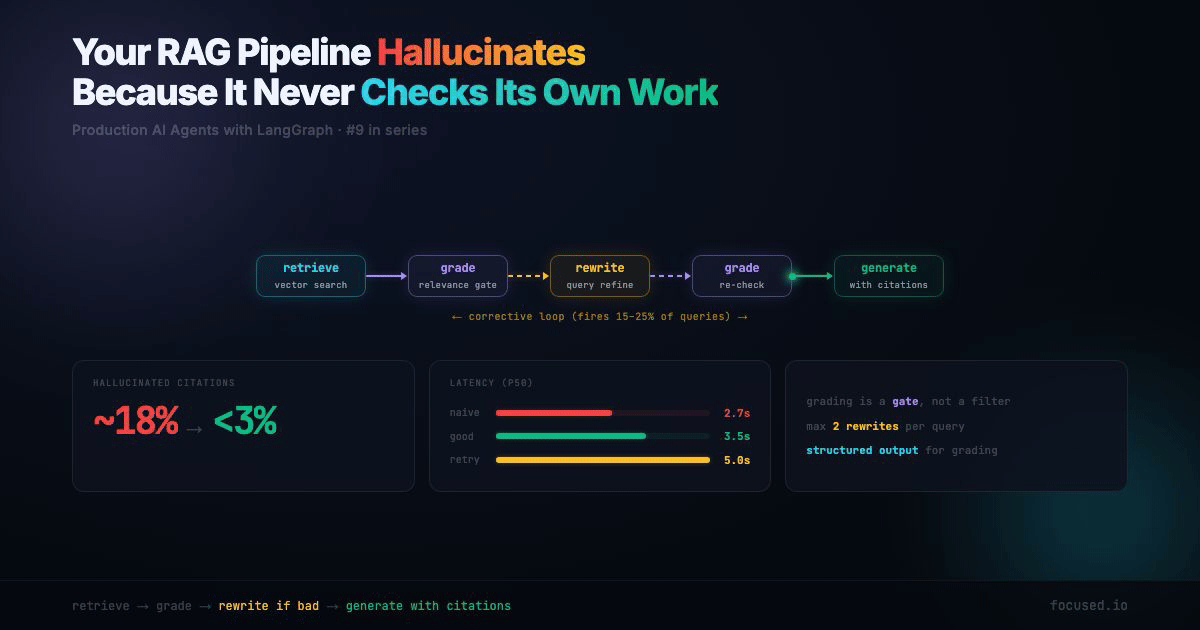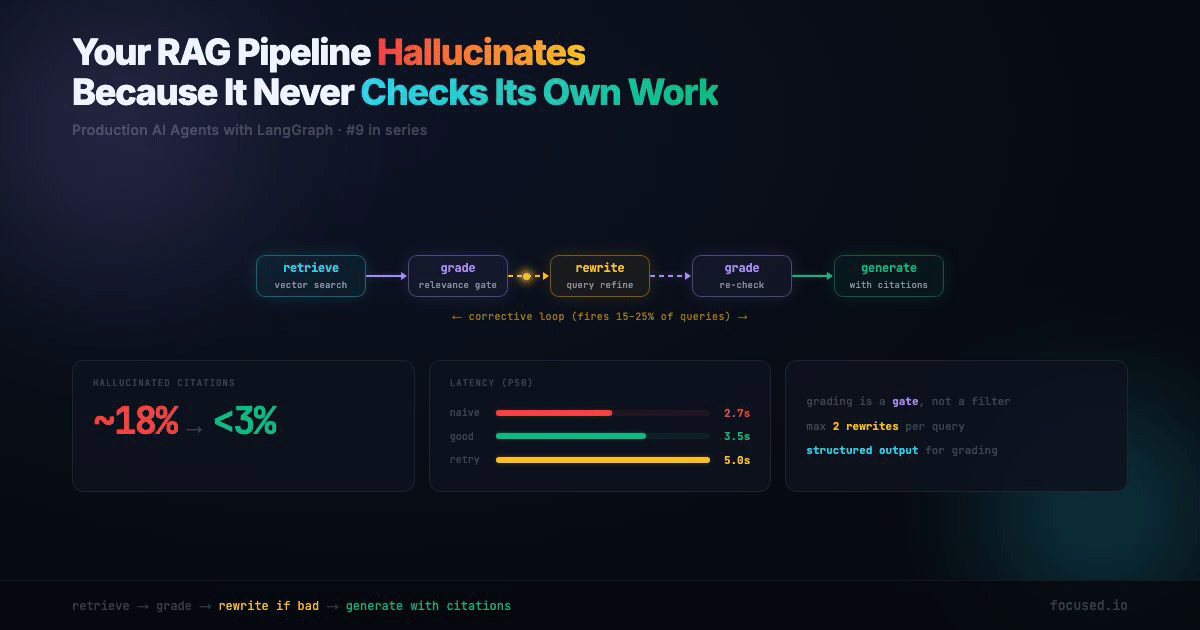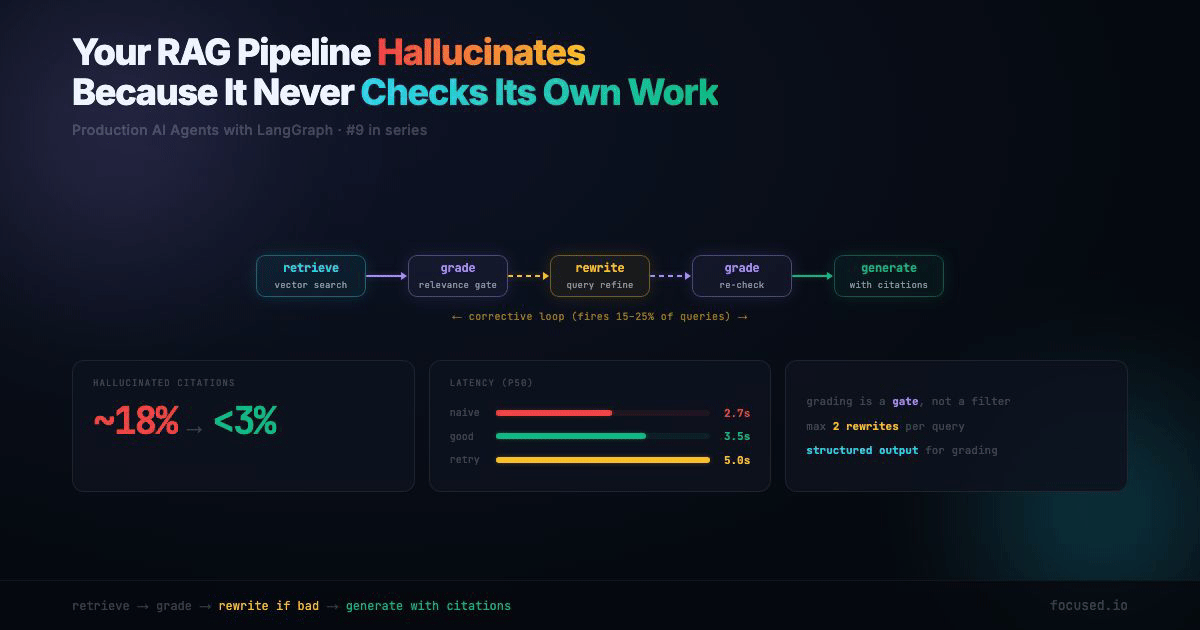
This post builds a corrective RAG pipeline using LangGraph. Retrieve, grade, rewrite if needed, generate with citations. The architecture adds ~1.5 seconds of latency on the retry path but drops hallucinated citations from ~18% to under 3% in our evals. That's not a prompt trick — it's structural.
The Latency Math
Naive RAG is fast because it skips the hard parts:
Corrective RAG adds grading and optional rewriting:
The retry path costs 1.5 seconds extra. But it only fires when retrieval quality is low — roughly 15-25% of queries in a typical technical docs corpus. The alternative is hallucinating an answer 100% of those times. That math is easy.
The Corrective RAG Pipeline Architecture
┌──────────────┐
│ Retrieve │
└──────┬───────┘
│
┌──────▼───────┐
┌───│ Grade Docs │───┐
│ └──────────────┘ │
relevant not relevant
│ │
│ ┌──────▼───────┐
│ │ Rewrite Query │
│ └──────┬───────┘
│ │
│ ┌──────▼───────┐
│ │ Re-Retrieve │──→ (back to Grade)
│ └──────────────┘
│
┌──────▼───────┐
│ Generate │
└──────┬───────┘
│
ENDThe key insight: grading is a gate, not a filter. If the retrieved documents don't answer the question, the pipeline doesn't generate a worse answer — it rewrites the query and tries again. After a configurable number of retries, it generates with a "low confidence" flag rather than hallucinating.
State: Track Everything
RAG state needs more than question and answer. You need to track retrieval quality, rewrite count, and the documents themselves — because your evals will need all of it.
from typing import TypedDict
from langchain_anthropic import ChatAnthropic
from langsmith import traceable
llm = ChatAnthropic(model="claude-sonnet-4-5-20250929", temperature=0)
class RAGState(TypedDict):
question: str
rewritten_query: str
documents: list[dict]
relevance_score: float
rewrite_count: int
max_rewrites: int
answer: str
citations: list[dict]
confidence: strDocument Ingestion
Before the pipeline runs, documents need to be split, embedded, and indexed. This is the part most tutorials skip — and where most production RAG systems break
from langchain_core.documents import Document
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
DOCS = [
Document(
page_content=(
"The Batch API allows you to send up to 50,000 requests in a single batch. "
"Each batch is processed asynchronously and results are available within 24 hours. "
"Rate limits for the Batch API are separate from real-time API limits. "
"Maximum batch size is 100MB per file."
),
metadata={"source": "api-docs/batch-api.md", "section": "overview"},
),
Document(
page_content=(
"Real-time API rate limits depend on your tier. Tier 1: 500 RPM, 30,000 TPM. "
"Tier 2: 2,000 RPM, 120,000 TPM. Tier 3: 5,000 RPM, 600,000 TPM. "
"Rate limit errors return HTTP 429. Implement exponential backoff."
),
metadata={"source": "api-docs/rate-limits.md", "section": "tiers"},
),
Document(
page_content=(
"Authentication uses API keys passed via the Authorization header. "
"Keys are scoped to organizations. Rotate keys every 90 days. "
"Never commit API keys to version control."
),
metadata={"source": "api-docs/authentication.md", "section": "keys"},
),
Document(
page_content=(
"The streaming endpoint supports Server-Sent Events (SSE). "
"Connect to /v1/stream with your API key. Events include 'message.delta', "
"'message.complete', and 'error'. Connection timeout is 5 minutes of inactivity."
),
metadata={"source": "api-docs/streaming.md", "section": "sse"},
),
Document(
page_content=(
"Error codes: 400 Bad Request (malformed JSON), 401 Unauthorized (invalid key), "
"403 Forbidden (insufficient permissions), 404 Not Found (invalid endpoint), "
"429 Too Many Requests (rate limited), 500 Internal Server Error (retry with backoff)."
),
metadata={"source": "api-docs/errors.md", "section": "codes"},
),
]
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
add_start_index=True,
)
splits = text_splitter.split_documents(DOCS)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = InMemoryVectorStore.from_documents(splits, embeddings)
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
Chunk size matters more than you think. Too small (100 chars) and you lose context — the retriever returns sentence fragments that the grader can't evaluate. Too large (2000+ chars) and you dilute relevance — a chunk about "rate limits AND authentication AND billing" matches everything and answers nothing. 500 characters with 50-char overlap is a reasonable starting point for technical docs. Measure it with your evals, not your intuition.
Node 1: Retrieve
The retriever converts the query into an embedding, searches the vector store, and returns the top-k documents. Simple — and the node most people over-engineer.
@traceable(name="retrieve", run_type="retriever")
def retrieve_node(state: RAGState) -> dict:
query = state.get("rewritten_query") or state["question"]
results = retriever.invoke(query)
documents = [
{
"content": doc.page_content,
"metadata": doc.metadata,
}
for doc in results
]
return {"documents": documents}
Notice: we use rewritten_query if it exists, otherwise fall back to the original question. This is how the retry loop works — the rewrite node updates rewritten_query, and the retriever picks it up on the next pass.
Node 2: Grade Relevance
This is the node that makes corrective RAG work. Use structured output to get a binary relevance score from the LLM:
from pydantic import BaseModel, Field
class RelevanceGrade(BaseModel):
"""Grade the relevance of retrieved documents to the user question."""
relevant: bool = Field(
description="Are the documents relevant to answering the question?"
)
reasoning: str = Field(
description="Brief explanation of the relevance assessment."
)
grading_llm = llm.with_structured_output(RelevanceGrade)
@traceable(name="grade_relevance", run_type="chain")
def grade_node(state: RAGState) -> dict:
docs_text = "\n\n".join(
f"[Source: {d['metadata'].get('source', 'unknown')}]\n{d['content']}"
for d in state["documents"]
)
grade = grading_llm.invoke([
{
"role": "system",
"content": (
"You are a relevance grader. Given a user question and retrieved documents, "
"determine if the documents contain information that can answer the question. "
"Be strict: if the documents are tangentially related but don't actually "
"answer the question, mark as not relevant."
),
},
{
"role": "user",
"content": (
f"Question: {state['question']}\n\n"
f"Retrieved documents:\n{docs_text}"
),
},
])
return {
"relevance_score": 1.0 if grade.relevant else 0.0,
}
Why structured output instead of a prompt that says "respond yes or no"? Because free-text parsing is brittle. The LLM might say "Yes, mostly relevant" or "Somewhat" or "The documents partially address..." and now you're writing regex. with_structured_output forces a clean boolean — no parsing, no ambiguity, no silent failures when the LLM gets creative with its formatting.
Node 3: Rewrite Query
When retrieval quality is low, rewrite the query to be more specific. The LLM sees the original question and the failed documents, so it can identify what's missing:
@traceable(name="rewrite_query", run_type="chain")
def rewrite_node(state: RAGState) -> dict:
failed_docs = "\n".join(
d["content"][:200] for d in state["documents"]
)
response = llm.invoke([
{
"role": "system",
"content": (
"You are a query rewriter. The original query returned irrelevant documents. "
"Rewrite the query to be more specific and targeted. "
"Focus on the key technical terms and concepts the user is asking about. "
"Return ONLY the rewritten query, nothing else."
),
},
{
"role": "user",
"content": (
f"Original question: {state['question']}\n\n"
f"Documents returned (not relevant):\n{failed_docs}\n\n"
"Rewrite the query to find more relevant documents:"
),
},
])
return {
"rewritten_query": response.content,
"rewrite_count": state["rewrite_count"] + 1,
}Node 4: Generate with Citations
The generator doesn't just produce an answer — it maps every claim to a source document. This makes hallucination detectable:
@traceable(name="generate", run_type="chain")
def generate_node(state: RAGState) -> dict:
docs_text = "\n\n".join(
f"[{i+1}] (Source: {d['metadata'].get('source', 'unknown')})\n{d['content']}"
for i, d in enumerate(state["documents"])
)
is_low_confidence = state.get("relevance_score", 0) < 1.0
system_prompt = (
"You are a technical documentation assistant. Answer the user's question "
"using ONLY the provided documents. For every claim, cite the source using "
"[1], [2], etc. If the documents don't contain enough information to fully "
"answer the question, say so explicitly — do not make up information."
)
if is_low_confidence:
system_prompt += (
"\n\nWARNING: The retrieved documents may not be fully relevant to the question. "
"Be especially careful to only state what the documents support. "
"Prefix your answer with 'Note: This answer is based on limited context.'"
)
response = llm.invoke([
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": (
f"Question: {state['question']}\n\n"
f"Documents:\n{docs_text}"
),
},
])
citations = [
{"index": i + 1, "source": d["metadata"].get("source", "unknown")}
for i, d in enumerate(state["documents"])
]
confidence = "low" if is_low_confidence else "high"
return {
"answer": response.content,
"citations": citations,
"confidence": confidence,
}
Graph Assembly
The routing logic is where the corrective pattern lives. Grade → decide → rewrite or generate:
from langgraph.graph import StateGraph, START, END
from langgraph.types import RetryPolicy
def route_after_grading(state: RAGState) -> str:
if state.get("relevance_score", 0) >= 1.0:
return "generate"
if state["rewrite_count"] >= state["max_rewrites"]:
return "generate"
return "rewrite"
builder = StateGraph(RAGState)
builder.add_node("retrieve", retrieve_node, retry=RetryPolicy(max_attempts=3))
builder.add_node("grade", grade_node, retry=RetryPolicy(max_attempts=3))
builder.add_node("rewrite", rewrite_node, retry=RetryPolicy(max_attempts=3))
builder.add_node("generate", generate_node, retry=RetryPolicy(max_attempts=3))
builder.add_edge(START, "retrieve")
builder.add_edge("retrieve", "grade")
builder.add_conditional_edges(
"grade",
route_after_grading,
{"generate": "generate", "rewrite": "rewrite"},
)
builder.add_edge("rewrite", "retrieve")
builder.add_edge("generate", END)
graph = builder.compile()The rewrite → retrieve → grade cycle is the corrective loop. max_rewrites caps it at 2 by default — enough to refine a vague query, not enough to burn through your API budget on a genuinely unanswerable question.
Running the Pipeline
from langsmith import tracing_context
with tracing_context(
metadata={"pipeline": "corrective-rag", "version": "v1"},
tags=["production", "rag-v1"],
):
result = graph.invoke({
"question": "What are the rate limits for the batch API?",
"rewritten_query": "",
"documents": [],
"relevance_score": 0.0,
"rewrite_count": 0,
"max_rewrites": 2,
"answer": "",
"citations": [],
"confidence": "",
})
print(f"Answer: {result['answer']}")
print(f"Confidence: {result['confidence']}")
print(f"Rewrites: {result['rewrite_count']}")
print(f"Citations: {result['citations']}")Production RAG Pipeline Failures
These are the failure modes that separate a demo from a production system.
1. Retrieval Drift. The query is "batch API rate limits" and the retriever returns documents about real-time API rate limits. The content is about rate limits, so naive RAG generates a confident answer — about the wrong API. The grading node catches this because "Tier 1: 500 RPM" doesn't answer a question about batch processing. Fix: the relevance grader needs to be strict about whether documents answer this specific question, not just whether they're in the same topic area.
2. Hallucinated Citations. The generator cites "[1]" but the claim it's supporting doesn't appear in document [1]. The citation exists, the source exists, but the mapping between claim and source is fabricated. This is almost impossible to catch without a dedicated faithfulness eval. Fix: the citations field in state makes this auditable. Your eval checks whether each cited claim is actually supported by the cited document.
3. Context Window Overflow. You retrieve 10 documents at k=10, each is 500 chars. That's 5,000 chars of context before the question and system prompt. Sounds fine. Then a user asks a compound question, the rewriter expands it, and on the second retrieval pass you're stuffing 10,000 chars of context. The generator starts ignoring the later documents. Fix: cap total context length, not just k. And put the most relevant documents first — LLMs have a recency and primacy bias even in their context window.
4. Rewrite Loop Hallucination. The rewriter makes the query more specific but also less accurate. "What's the rate limit?" becomes "What is the maximum requests per second for the enterprise streaming endpoint?" — a question that's more specific but targets a concept that doesn't exist in your docs. The second retrieval is even worse. Fix: the rewriter should see the failed documents so it knows what the corpus actually contains. Our implementation passes failed_docs to the rewriter for exactly this reason.
5. Embedding Staleness. Your docs update weekly. Your embeddings update monthly. For three weeks out of every four, the retriever is searching a stale index. New features return zero results; deprecated features return confident but wrong answers. Fix: re-index on every doc update. If that's too expensive, at minimum track the embedding timestamp and surface a "stale index" warning when results are older than your update threshold.
Observability
The @traceable decorator on every node gives you per-step visibility in LangSmith. For RAG specifically, you want to see the retrieval→grading→generation flow in one trace:
from langsmith import tracing_context
with tracing_context(
metadata={
"rag_version": "corrective-v1",
"corpus_size": len(splits),
"embedding_model": "text-embedding-3-small",
},
tags=["production", "corrective-rag"],
):
result = graph.invoke({
"question": "How do I authenticate with the API?",
"rewritten_query": "",
"documents": [],
"relevance_score": 0.0,
"rewrite_count": 0,
"max_rewrites": 2,
"answer": "",
"citations": [],
"confidence": "",
})In the LangSmith trace, you can see:
- The retriever span showing which documents were returned and their similarity scores
- The grading span showing the structured relevance assessment
- Whether the rewrite loop fired (and how many times)
- The generator span showing the final prompt with context
- Total token usage and latency per node
The first thing to check when answer quality degrades: are rewrites spiking? If rewrite_count averages above 0.5 across queries, your retrieval quality has drifted — probably stale embeddings or a corpus change that shifted the embedding space.
Evals for Retrieval Augmented Generation
RAG evals need three axes: retrieval quality, answer faithfulness, and answer relevance. Skipping any one of them leaves a blind spot that will eventually become a production incident.
from langsmith import Client, evaluate
from openevals.llm import create_llm_as_judge
ls_client = Client()
dataset = ls_client.create_dataset(
dataset_name="corrective-rag-evals",
description="Corrective RAG pipeline evaluation dataset",
)
ls_client.create_examples(
dataset_id=dataset.id,
inputs=[
{"question": "What are the rate limits for the batch API?"},
{"question": "How do I authenticate API requests?"},
{"question": "What error code means I've been rate limited?"},
{"question": "What is the connection timeout for streaming?"},
],
outputs=[
{"expected_topics": ["batch", "50,000", "asynchronous"], "expected_source": "api-docs/batch-api.md"},
{"expected_topics": ["API key", "Authorization header", "rotate"], "expected_source": "api-docs/authentication.md"},
{"expected_topics": ["429", "rate limit"], "expected_source": "api-docs/errors.md"},
{"expected_topics": ["5 minutes", "SSE", "timeout"], "expected_source": "api-docs/streaming.md"},
],
)FAITHFULNESS_PROMPT = """\
Question: {inputs[question]}
Retrieved documents: {outputs[documents]}
Generated answer: {outputs[answer]}
Rate 0.0-1.0 on faithfulness: Is every claim in the answer supported by the retrieved documents?
A score of 1.0 means no hallucinated information. A score of 0.0 means the answer fabricates claims.
Return ONLY: {{"score": <float>, "reasoning": "<explanation>"}}"""
RELEVANCE_PROMPT = """\
Question: {inputs[question]}
Generated answer: {outputs[answer]}
Rate 0.0-1.0 on relevance: Does the answer actually address the user's question?
A score of 1.0 means the answer directly and completely addresses the question.
A score of 0.0 means the answer is off-topic or doesn't address the question.
Return ONLY: {{"score": <float>, "reasoning": "<explanation>"}}"""
faithfulness_judge = create_llm_as_judge(
prompt=FAITHFULNESS_PROMPT,
model="anthropic:claude-sonnet-4-5-20250929",
feedback_key="faithfulness",
)
relevance_judge = create_llm_as_judge(
prompt=RELEVANCE_PROMPT,
model="anthropic:claude-sonnet-4-5-20250929",
feedback_key="relevance",
)
def retrieval_precision(inputs: dict, outputs: dict, reference_outputs: dict) -> dict:
"""Did the retriever find documents from the expected source?"""
expected_source = reference_outputs.get("expected_source", "")
retrieved_sources = [
d.get("metadata", {}).get("source", "")
for d in outputs.get("documents", [])
]
hit = any(expected_source in s for s in retrieved_sources)
return {"key": "retrieval_precision", "score": 1.0 if hit else 0.0}
def topic_coverage(inputs: dict, outputs: dict, reference_outputs: dict) -> dict:
"""Does the answer mention the key topics?"""
answer = outputs.get("answer", "").lower()
topics = reference_outputs.get("expected_topics", [])
hits = sum(1 for t in topics if t.lower() in answer)
return {
"key": "topic_coverage",
"score": hits / len(topics) if topics else 1.0,
}
def rewrite_efficiency(inputs: dict, outputs: dict, reference_outputs: dict) -> dict:
"""How many rewrites were needed? Fewer is better."""
count = outputs.get("rewrite_count", 0)
if count == 0:
score = 1.0
elif count == 1:
score = 0.7
else:
score = 0.4
return {"key": "rewrite_efficiency", "score": score}
def target(inputs: dict) -> dict:
return graph.invoke({
"question": inputs["question"],
"rewritten_query": "",
"documents": [],
"relevance_score": 0.0,
"rewrite_count": 0,
"max_rewrites": 2,
"answer": "",
"citations": [],
"confidence": "",
})
results = evaluate(
target,
data="corrective-rag-evals",
evaluators=[
faithfulness_judge,
relevance_judge,
retrieval_precision,
topic_coverage,
rewrite_efficiency,
],
experiment_prefix="corrective-rag-v1",
max_concurrency=4,
)retrieval_precision is the canary. If it drops below 0.8, your embeddings are stale or your chunk size is wrong — fix the retrieval layer before touching prompts. faithfulness catches hallucinated citations. topic_coverage catches incomplete answers. rewrite_efficiency monitors whether the corrective loop is firing too often. Run all four on every PR that changes retrieval, prompts, or document processing.
When to Use This
- Your corpus has overlapping topics (rate limits for different APIs, config for different services)
- Wrong answers are worse than slow answers (legal, medical, financial docs)
- You need auditability — every answer traced back to source documents
- Your retrieval quality varies (some queries match perfectly, others return tangential results)
- Your corpus is small and well-differentiated (a 10-page FAQ)
- Latency budget is under 3 seconds
- You're building a search UI, not a Q&A system (show results, don't generate answers)
- Retrieval quality is consistently high (>95% of queries return relevant doc
The Bottom Line
Naive RAG is a demo. Corrective RAG is a system. The difference is a grading node, a rewrite loop, and a confidence flag — maybe 40 lines of extra code and 1.5 seconds of extra latency on the retry path.
The architecture is: retrieve, grade, rewrite if bad, generate with citations. The grading node is the key — without it, you're trusting the retriever to be right every time, and it won't be. The citations field makes hallucinations detectable. The rewrite loop makes bad queries fixable. The confidence flag tells the caller when to trust the answer and when to escalate.
Ship the faithfulness eval before you ship the pipeline. If your retrieval precision drops below 0.8, fix your embeddings before you fix your prompts. And set max_rewrites to 2 — if two query rewrites can't find relevant context, a third won't either.
Austin Vance is the CEO of Focused, where we build AI-powered software that solves complex problems in production. If you're building RAG pipelines and want to talk retrieval strategies, reach out.
Technical References:
Corrective RAG pipeline GitHub Repo
Build a custom RAG agent with LangGraph
/Contact Us

Modernize your legacy with Focused
Get in touch