LangChain
Parallel execution with LangChain and LangGraph.
Learn how to significantly speed up LangChain and LangGraph agent workflows with parallel execution. A straightforward, powerful technique for faster results.
Apr 25, 2025
When building effective agent architectures, it's essential to start with strong foundational concepts. One of the most powerful building blocks in modern agent workflows is parallel execution, particularly when working with frameworks like LangChain and LangGraph.
If you've worked with LLM-based agents, you're likely familiar with the pain of slow response times. Each user interaction often triggers multiple sequential LLM calls, causing noticeable delays and negatively impacting the user experience. To address this, parallel execution is your best ally.
Let's examine this using a common scenario, Retrieval Augmented Generation (RAG). Typically, the workflow involves searching the web, querying a vector database, and then aggregating the results. Executing these steps sequentially:
search_web → search_vector_db → aggregate_results
is straightforward but inherently slow.
The powerful alternative is to execute these calls simultaneously. By introducing parallel execution, both the web search and vector database query occur at the same time, dramatically cutting down the total execution time.
Here's how easily you can implement parallel execution by modifying just four lines of code:
Instead of the sequential version:
builder.add_edge(START, "search_web")
builder.add_edge("search_web", "search_vector_db")
builder.add_edge("search_vector_db", "aggregate_results")
builder.add_edge("aggregate_results", END)Which gives a graph like this:
(Sequential execution diagram - image needs to be re-uploaded)
Use this parallel execution configuration:
builder.add_edge(START, "search_vector_db")
builder.add_edge("search_web", "aggregate_results")
builder.add_edge("search_vector_db", "aggregate_results")
builder.add_edge("aggregate_results", END)Which gives a graph like this:
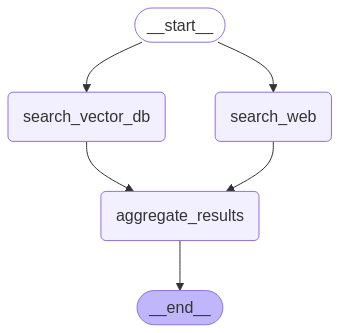
The key difference is simple yet transformative — both search_web and search_vector_db nodes initiate concurrently from the same start point. With minimal effort, your application now handles tasks far more efficiently, significantly enhancing user experience.
Interested in seeing this in action or experimenting with more advanced examples? Check out the full source code in our repository and follow along as we continue expanding this resource:
/Contact Us

Modernize your legacy with Focused
Get in touch