Blog
Agent Skills Are a Software Supply Chain Surface
Agent skills are becoming executable supply-chain artifacts. Govern them with provenance, permissions, sandbox policies, eval gates, trace evidence, and rollback.
May 28, 2026

Agent skills, designed to serve as instructional features for developers building applications using agentic AI, are increasingly becoming supply-chain features that developers can download and execute. Agent skills packaged as code and distributed through marketplaces are becoming what I refer to as “executable supply-chain artifacts”. Like any other software feature, these artifacts can have code shaped power wrapped in a friendly-looking markdown jacket.
As AI agent skills are distributed through marketplaces and enterprise tools, the security world has to examine them as executable artifacts. A new paper, “An Empirical Study on Malicious AI Agent Skills in Marketplaces,” found that 76 of 3,984 total AI agent skills in marketplaces contained malicious payloads for credential theft, backdoor installation, and data exfiltration. The authors also found that 13.4% contained at least one critical issue after manual review. They confirmed that eight malicious skills were still available in one of the marketplaces they studied at publication time (arXiv, 2026).
That changes the conversation around agentic AI security.
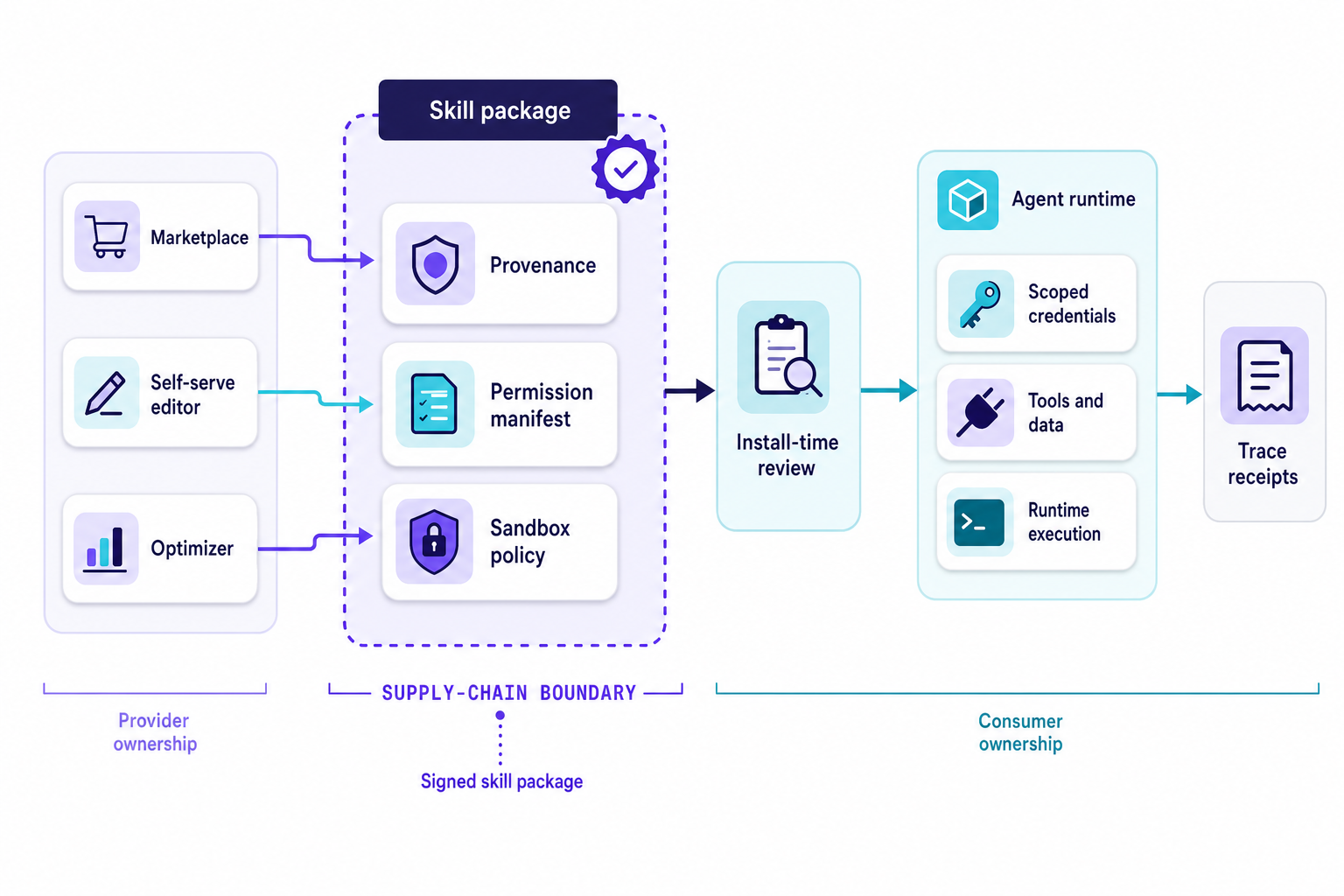
The skill file has become a package boundary.
Skills are becoming packages
About a year ago we would show a skill file that was essentially a repository of an application, next to a set of rules written by a developer for a model such as Claude Code, Cursor, an agent, or workflow assistant. That repository of rules would give the model additional context or habits for how to process a query or workflow, such as being able to extract information from a complex table or generate supporting text for a given prompt.
Now the pattern has grown teeth.
The problem is that shortcuts cross trust boundaries.
A skill package has to answer plain questions: Who was the owner of the skill, what did it do, where did it get executed, what credentials were in use, what tools were used, what was the configuration of the tool’s sandbox, what were the results of the evaluations for the skill, what traces were produced by the skill, what user action started it, how rollback works for that user.
Honeycomb announced Agent Skills in the form of eight skills, two agents, and workflows that encode the observability expertise required to instrument, observe, and debug OpenTelemetry-enabled production services and migrate from distributed tracing systems into observability stacks (Honeycomb, 2026). Lyft built a self-serve platform with LangGraph and LangSmith for domain experts to define custom agents, while the platform manages the underlying graph, tools, safety, state, tracing, dashboards, and LLM-as-a-judge evaluation (LangChain, 2026).
That is the right direction for adoption.
Governance has to move with that power.
This is directly related to agent monitoring as an infrastructure workload. That note cautioned against monitoring individual model calls. For skills, monitoring has to track the installed artifact, runtime permissions, traces, user actions, and recovery process.
Incident review then starts with ‘how did we feel’ instead of examining the facts of the incident.
The optimizer makes the boundary harder
There are also techniques that treat the skill file as external state for a frozen agent and use scored rollouts to inform bounded edits on the skill document. SkillOpt reports wins or ties in 52 out of 52 model, benchmark, or harness comparisons across direct chat, Codex-based chat, and Claude Code-based chat (SkillOpt, 2026). SkillGrad treats the skill package as a parameter and uses trajectory-level loss to patch the package over time (SkillGrad, 2026).
The manifest of a skill in serious skill systems includes a list of tools that the skill invokes, a list of files that the skill reads and/or writes to, a list of network locations that the skill connects to, a list of secrets that the skill can request, a list of data classes that the skill can read, and a list of human approvals that are needed for a skill to perform an action that could affect data external to the skill.
Reviews do not make skills safe forever. A reviewed skill can go into production clean, then run through evals, production traces, failed tasks, and large tests. The habits it picks up may be useful. They may also add permission, relax assumptions, or change data handling through a single text edit that looked safe because it passed review and scored high.
Agyn defines “definition of an agent” in this context as “code through a Terraform provider (e.g., provisioning a function), a signal-driven stateful serverless runtime on Kubernetes (e.g., a Python loop processing events), and a zero-trust, least-privilege security model for agents that hold state and access internal services” (Agyn, 2026). In summary, the shape of an agent as a piece of infra to be governed is the intersection of its definition (as code), its runtime (as a serverless process), and the corresponding boundaries on permissions that it must operate within as a state holding, service accessing agent.
More problems arise because skills are packaged in readable files and can be dropped into workflows quickly. Package managers with no provenance tracking become malware distribution channels. CI/CD pipelines with no scoped credentials become secret leak engines. Folklore around prompts, created through limited reproduction or no change history, enables suboptimal agents to be built and deployed through self-serve platforms.
If we assign a skill to write out release notes, it will be in a small sandbox. A skill that updates billing / refund information for customers / production data / source code / users’ identities should be in a totally different box and inherit the same spending discipline we previously discussed in agentic payments.
Trusted vs. declared runtime behavior.
Self-serve agents move governance to the edge
Lyft’s description of customer support work shows the adoption pressure. Account access, damage claims, charge reviews, earnings disputes, and autonomous vehicle support are closer to support domain experts than a central MLE queue. Their old loop took months. The self-serve layer cut that loop to weeks while the platform managed state, tools, safety, and evaluation (LangChain, 2026).
For prompt libraries, the registry only needs to store the text of the prompts. For skill registries, the registry stores signed artifacts together with metadata for the artifacts: the owners, the diffs (if the artifact was created incrementally), validation results for the artifact, failure modes that are known to occur for the artifact, permission manifests for the artifact, sandbox profiles for the artifact, telemetry definitions for the artifact, and deprecation state for the artifact. The registry should enable the system to answer questions about incidents, not questions about content-library usage.
What changed last night? What skill versions did which agents run last night? What tools did these skills invoke? What eval gate evaluated updates for these skills? What credential scopes were active for these agents? What customer data were read or written by these agents? What is the process for rolling back an agent to a previous skill version? (Re)Installing an agent is presumably not sufficient to “roll back” an agent.)
Agent platforms are evolving to treat all of an agent’s skills as packages that can be run or installed, in effect treating operating knowledge the same way that a new product or feature would be packaged for distribution by an agent platform.
The minute something gets packaged, distribution outruns inspection.
Yes, there is a place for manual review, and it should be limited, though. Skills should pass static checks before they can be installed. Skills should declare what permissions they expect before it can be installed. Skills should run in a sandbox before they are promoted to full-scale task execution. The skill’s evals should be cleared before the skill is promoted to full-scale task execution. Skills should emit trace receipts during their execution. Skills should support a form of rollback after it misbehaves.
The governance model for skills has to go beyond a document and meeting. The deployment record should name the owner, track versions, show the diff for each change, define permissions, list in-scope credentials, list approved tools, define the sandbox configuration, list required evaluations, show runtime traces, record the user action that deployed the skill, and define a rollback plan.
The next set of incidents involving agents will be due to the skills executing on them.
This is directly related to our earlier note on agent monitoring as an infrastructure workload. Monitoring individual model calls is too narrow. For skills, the system has to monitor the installed artifact, runtime permissions, traces, user actions, and recovery process.
Then everyone asks who approved the agent.
This also maps onto our previous observation about trace evidence across the MCP boundary. The trace for a skill cannot simply be a transcript of a model conversation. It has to show the skill’s actions: what capability it requested, what credential it used, what tool calls it made, and what results came back.
Ask who approved the skill boundary.
Otherwise the incident review starts with vibes. Bad start.
We have spent real time on developing AI agency as if agency lives inside the model. Agency lives in the system: model, tools, runtime, memory, skills, and permission. Skills sit close to human expertise and close to runtime power. That combination is useful and dangerous.

The skill marketplace is coming. The governance boundary should get there first.
/Contact Us

Modernize your legacy with Focused
Get in touch